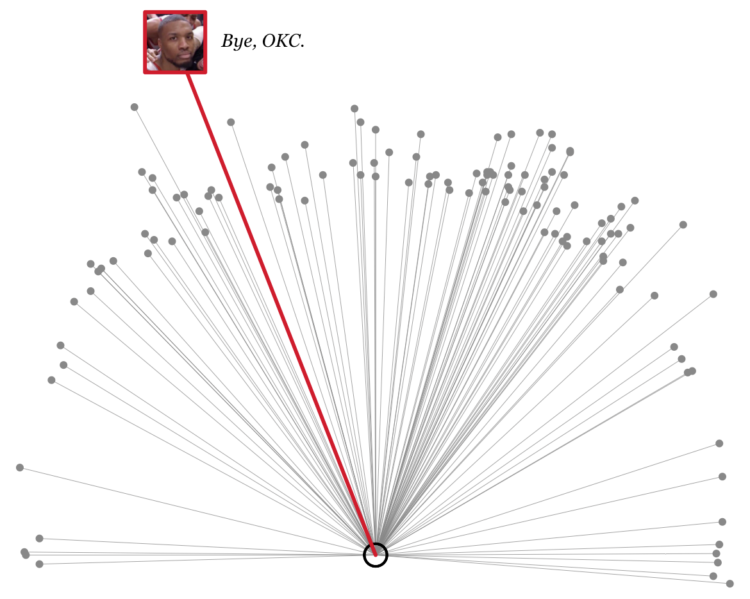
Jen Luker noted, “As amazing as @github is, it is a tool designed to track code, not people. I’m sharing my annotated GitHub history to show you what it can’t tell you about a developer.”
As amazing as @github is, it is a tool designed to track code, not people. I'm sharing my annotated GitHub history to show you what it can't tell you about a developer. pic.twitter.com/b94kYqQHaZ
— Jen Luker (@knitcodemonkey) April 25, 2019
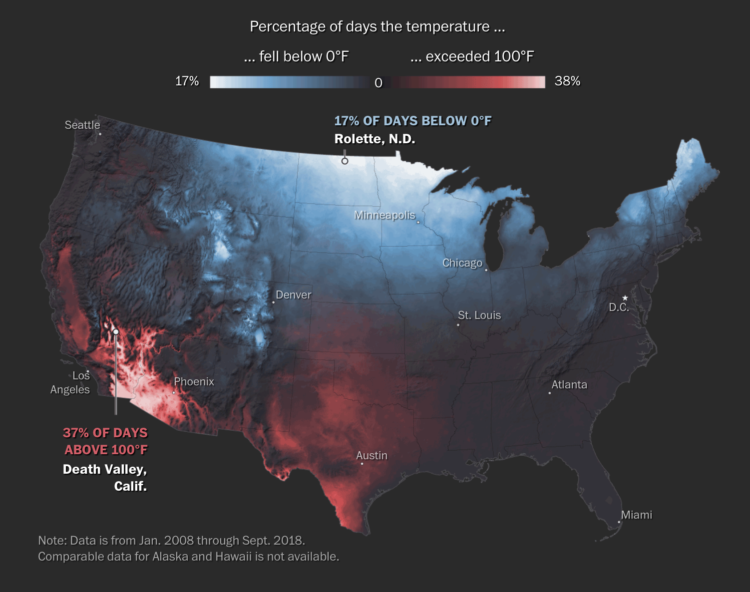
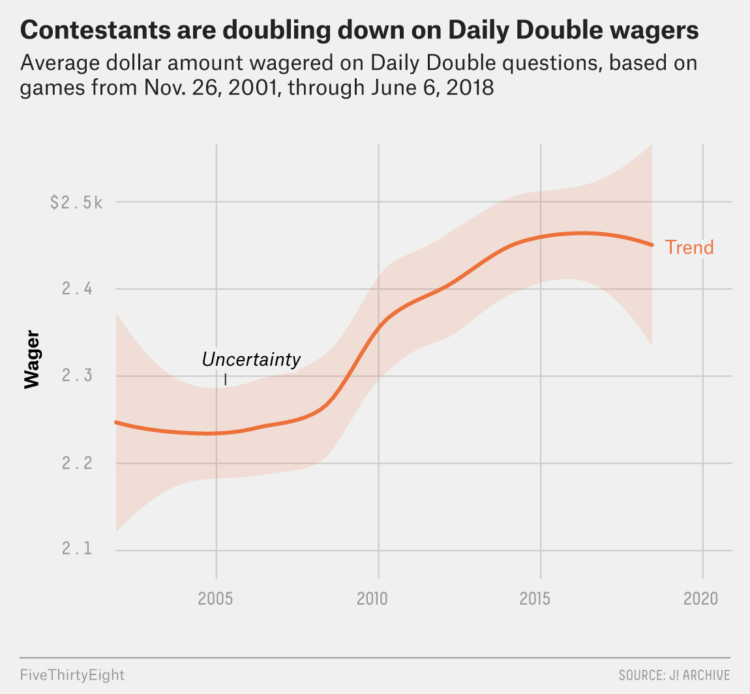
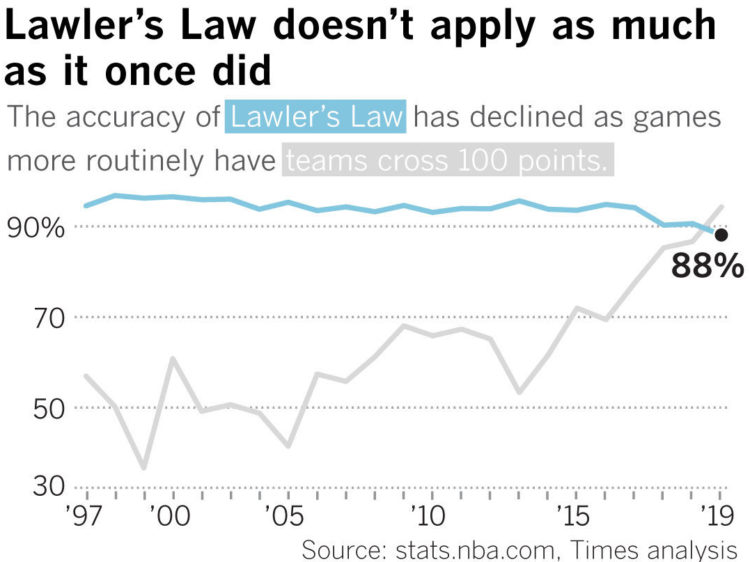
Data as footprints? Footprints can tell you where someone went, but you have to evaluate surroundings to figure out what he or she did along the way. And there’s a lot that can happen between when the footprints set and when you find them.






 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









