RJ Andrews held an exhibition of data graphics at 41 Cooper in New York. On physical data that exists off the screen:
After my presentation, I was asked about tools and gave my stock answer extolling paper and pencil as the most important creative weapon. This quip surprised me with the biggest applause of the night.
Beautiful information graphics off-screen, in the real world, are a real treat. In some sense the show did not feel special to me as much as it felt natural. The best way to consume data might not be alone on a pocket screen—but together, in conversation, with human-sized artifacts.
Andrews speaks of the satisfaction of such things but also of the challenges of handling physical data.
I’ve felt this with my own physical projects. It’s nice to hold the data. It’s real. It’s tangible.
It takes exponentially more time and effort.
But if we want visualization to extend beyond analytical tools and dashboards, then that’s what we will need to do.
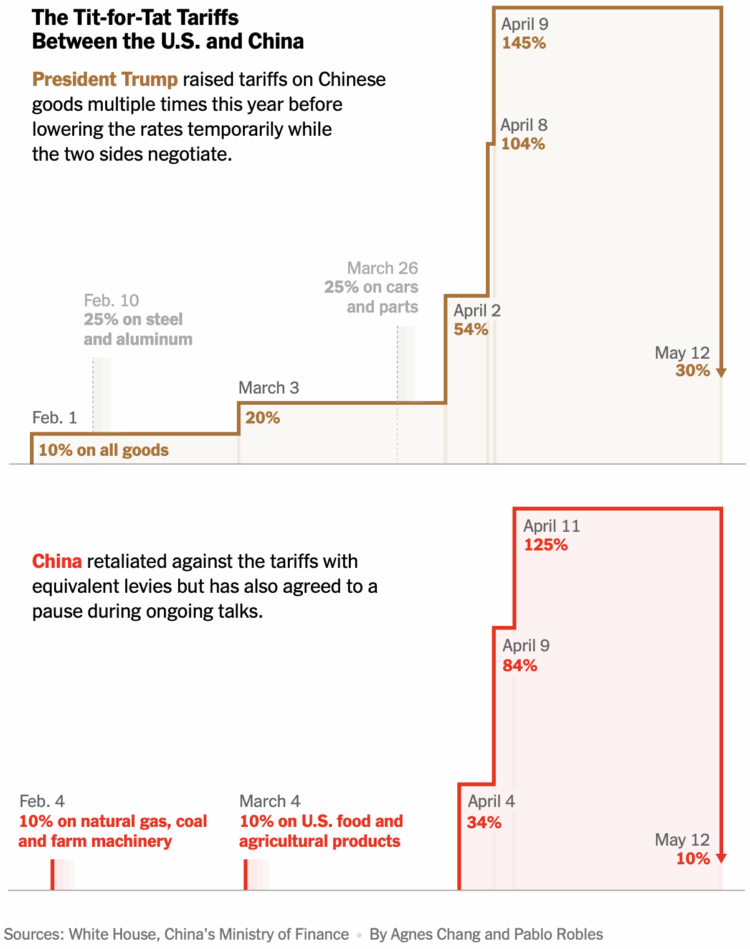

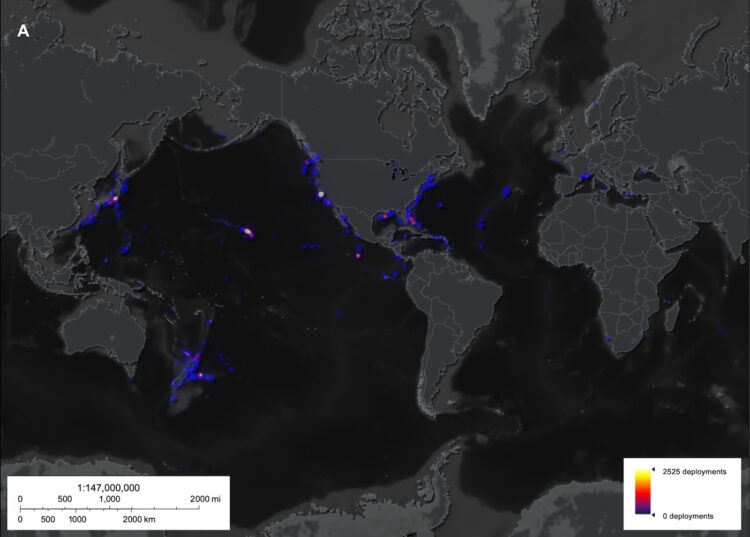
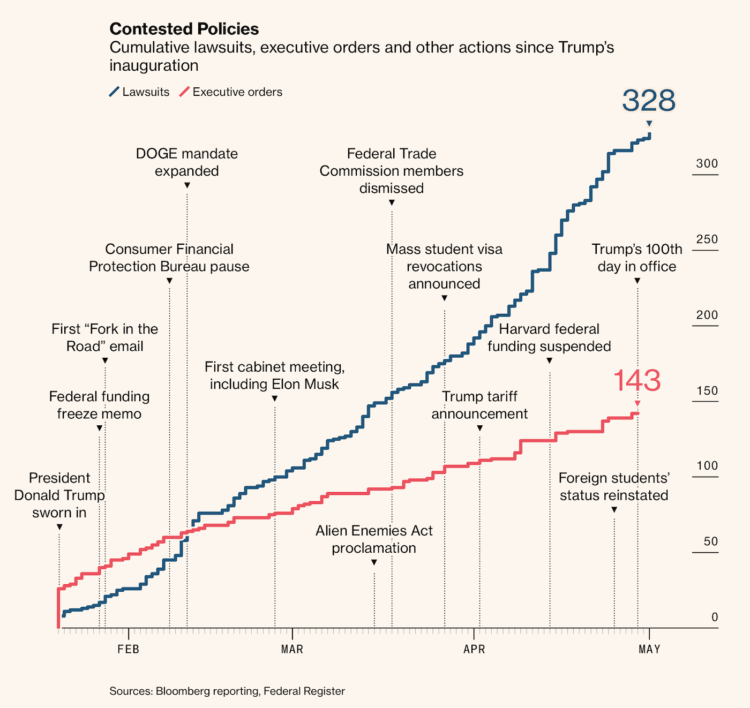
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









