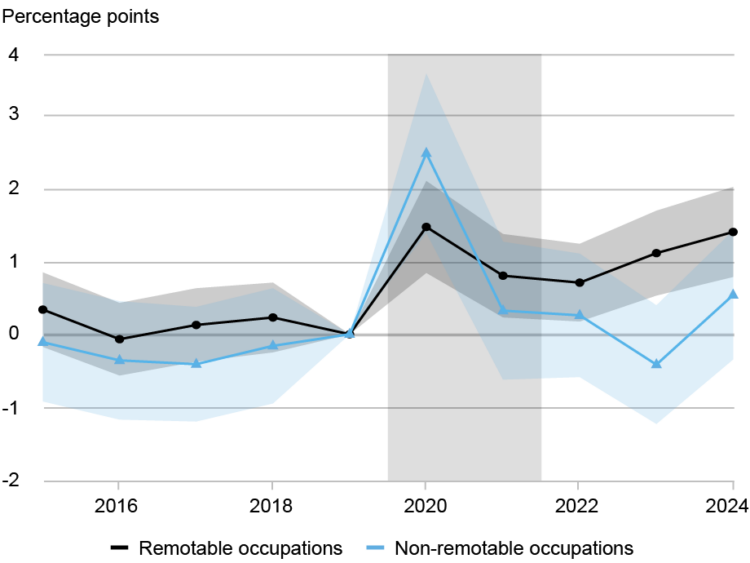
Higher unemployment among young workers has been commonly attributed to generative AI. In their paper from the National Bureau of Economic Research, Natalia Emanuel, Emma Harrington, and Amanda Pallais argue that the rise in remote work during Covid times is a bigger factor.
They compared unemployment for “remotable” and “non-remotable” jobs and then took the difference between younger and older workers:
The aggregate increase in the unemployment rate for young college graduates can be traced to remotable occupations, where young people’s unemployment rate increased by almost 1 percentage point between 2017-19 and 2022-24. By contrast, the unemployment rate of older workers in remotable sectors marginally declined over that period. As a result, the age gap in unemployment between younger and older workers significantly increased in remotable occupations. This relative increase in young people’s unemployment coincided with the pandemic and has remained elevated since then, as have rates of remote work.
The researchers further argue that AI is not yet a main factor for the shift in unemployment. In the chart above, note the sudden rise of the black line for remotable occupations in 2020, a slight taper afterwards, and then a continued rise.
Charts in the paper do need explaining and could use a layer of annotation, but the conclusions seem to make sense.




 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









