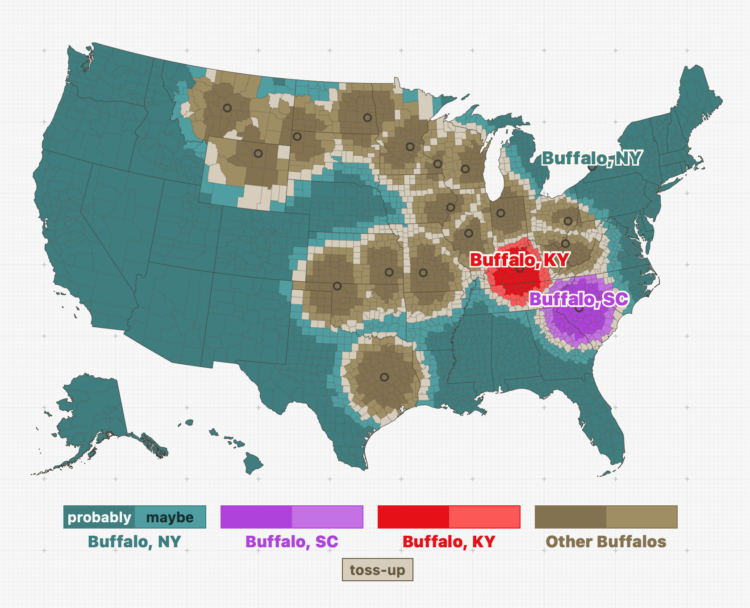
Throughout the United States, there are a surprising number of cities that have the same name. In fact, after playing with this interactive map by Russell Samora for The Pudding, it seems more likely that cities share a name with another than not. (Don’t quote me on that.)
The question is: When someone mentions a city, which one are they talking about? Samora calculated the likelihoods, given the county that person lives in. For example, when someone refers to Buffalo, most people are probably talking about Buffalo, New York. If you live in Buffalo, Kentucky, then probably not.
You can also mess around with your likelihood metric here.
See also: street names across the country.


 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









