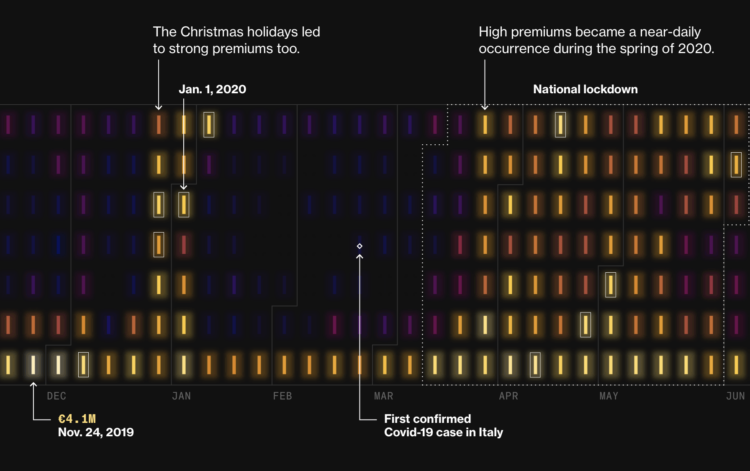
During Covid lockdowns, power companies in Italy charged premiums to cover increased prices for electricity, but it appears that isn’t the full story. For Bloomberg, Vernon Silver, Eric Fan, and Sam Dodge analyzed costs and premiums over time:
Even so, it’s clear – from executives’ celebratory comments during earnings calls as well as simple mathematics – that the dispatch market’s higher prices helped companies do far better than merely avoiding losses. In 2020 alone, dispatch premiums totaled €1.2 billion – or 238% more than companies would have received at the day-ahead price.
It looks like the power costs might partially be an excuse to charge more premiums. Maybe. Either way, I’m into the glowing aesthetic on the calendar heatmaps.








 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









