Here’s the good stuff for January.
Here’s the good stuff for January.
For Numberphile, Simon Anthony explains the Phistomephel Ring. The shape always contains the same numbers as the corners do. Math magic!
Meant to be comprehensive more than a curated collection, the Journalist’s Toolbox AI provides many links to tools that might help you data more efficiently. Or at least use more AI-ish things.
There’s still a long way to go before AI is reliable enough to analyze and make sense of data. A lot of these things still feel like half-baked gimmicks. However, for the mechanical, repetitive tasks that can be easily defined, such as scraping or coding chores, some of these resources might be useful.
You can always count on the site for updates on visualization, data, and statistics. There’s also RSS and email. But someone told me you should meet the people where they are, so here are the other places you can find FD.
Instagram — Visual. More common to post less frequently. I have a feeling this might be where I end up in my social media travels.
X/Twitter — There was a time when I had a Twitter app open all the time while I wrote my books and dissertation. It was a fun place for ideas and to share things. It’s in a weird place now, and it doesn’t seem to be getting better. So I’m still around, for now.
LinkedIn — Whoa. I have no idea what I’m doing in this career-focused place. But every couple of weeks someone posts one of my projects as their own and it gets thousands of interactions, so here I am.
YouTube — I animate data sometimes that works better in video format.
Reddit — The visualization-centric Subreddits can be overly critical and seem to have a high ratio of armchair chart experts. But I also want to know who took the flowingdata username and never posted many years ago. (It might have been me.)
Bluesky — As Twitter alternatives go, this might be it. I’m not sure if I want an alternative though.
Threads — Or maybe this? I don’t know it’s too much.
Mastodon — I’m here. It doesn’t seem like it’s for me. It took me three tries to spell mastodon correctly.
Facebook — Kind of. There’s been an FD page for years but I often forget it exists.
Social media is at a crossroads, so I’m kicking the tires on everything at this point. See you there.
In an effort to find a suspect in a 1990 murder, there was a police request in 2017 to use a 3-D rendering of a face based on DNA. For Wired, Dhruv Mehrotra reports:
The detective’s request to run a DNA-generated estimation of a suspect’s face through facial recognition tech has not previously been reported. Found in a trove of hacked police records published by the transparency collective Distributed Denial of Secrets, it appears to be the first known instance of a police department attempting to use facial recognition on a face algorithmically generated from crime-scene DNA.
This seems like a natural progression, but it should be easy to see how the pairing of the tech could cause all sorts of issues when someone’s face is poorly constructed and then misclassified with facial recognition. What’s the confidence interval equivalent for a face?
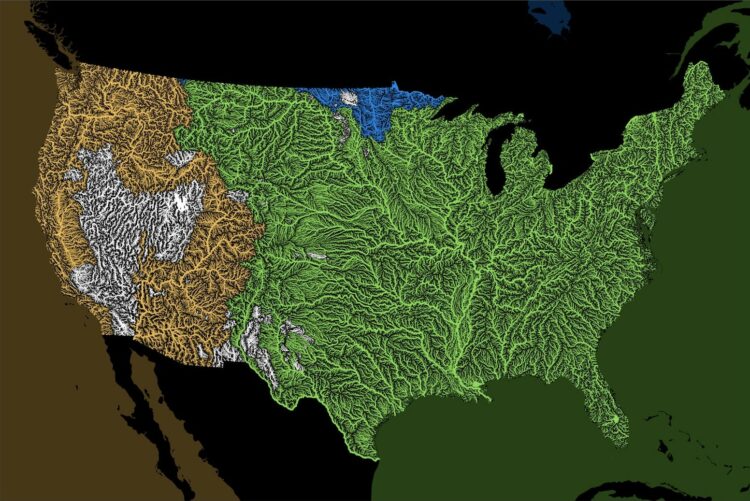
Rivers drain into oceans. Grasshopper Geography color-coded the rivers in the world by the ocean they drain into and made a series of maps.
But what is an ocean drainage basin map, I hear most of you asking? A couple of years ago I tried to find a map that shows in which ocean does each of the world’s rivers end up. I was a bit surprised to see there is no map like that, so I just decided I’ll make it myself – as usual. Well, after realizing all the technical difficulties, I wasn’t so surprised any more that it didn’t exist.
It reminds me of the map that shows where a raindrop ends up.
If you’re into basketball data, Sravan Pannala is keeping a running list of data sources, apps, and visualization on the topic. I can always use more basketball data, so I’ll bookmark this for later.
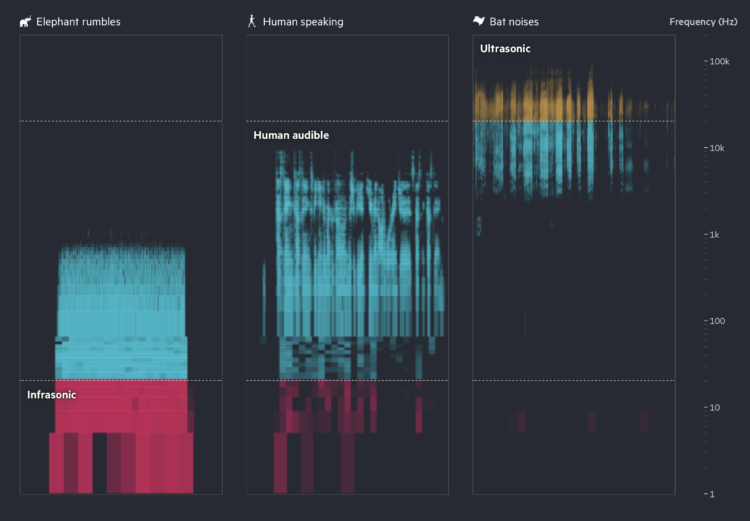
Financial Times highlights how researchers are using AI to try to learn what animal sounds mean and to communicate back. Turn on the sound for maximum effect.
Welcome to The Process, the newsletter for FlowingData members that looks closer at…
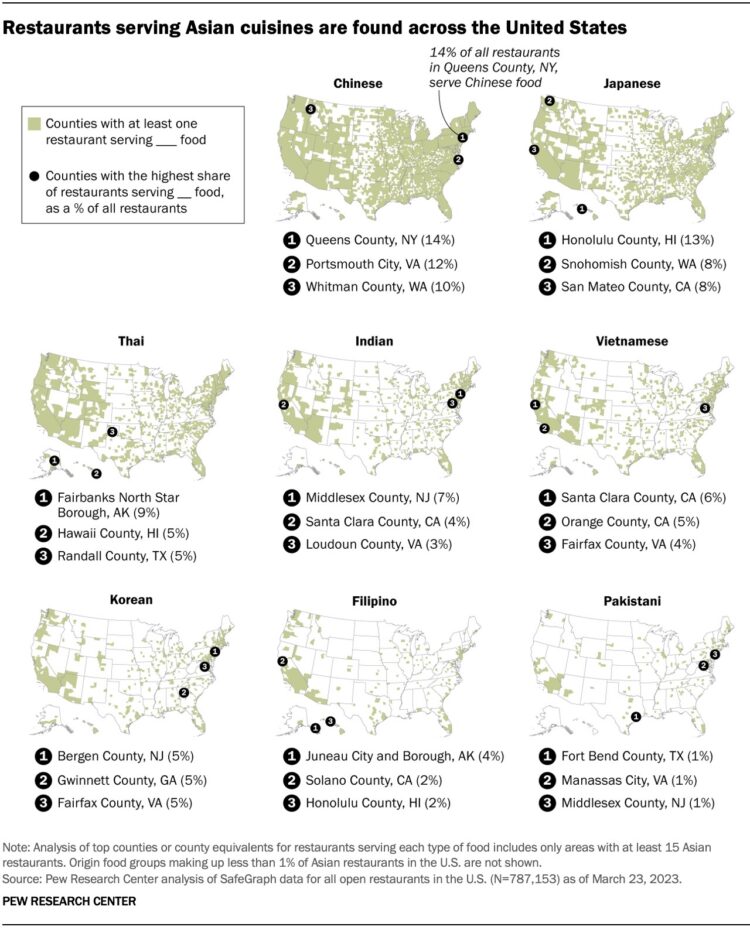
You can find Asian restaurants in most places in the United States, but the type of Asian food choices varies. For Pew Research, Sona Shah and Regina Widjaya mapped the distributions of eight major cuisines.
Whenever I’m in a new place, I like to check out the Chinese restaurants, because they’re everywhere. It’s fun to taste the area’s version of universal Chinese dishes. I’ve been to Queens. Now I’m curious about Portsmouth City and Whitman.
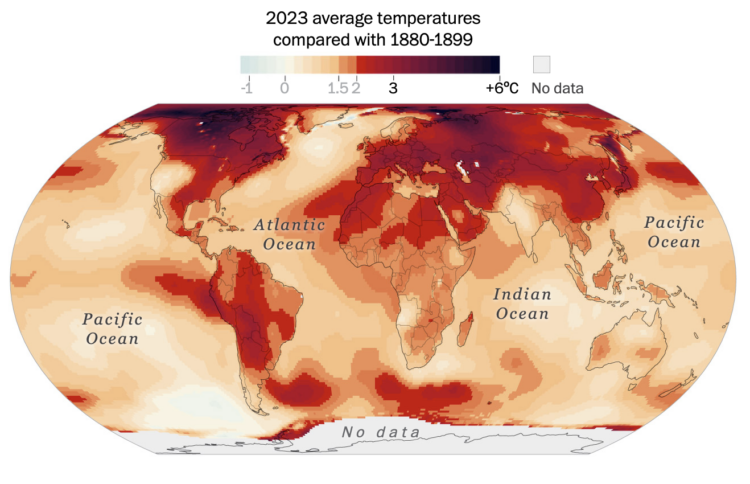
Earth got its hottest year on record in 2023. Based on data from Berkeley Earth, John Muyskens and Niko Kommenda, for The Washington Post, focused on the geographic areas that experienced the biggest jumps.
The Post has mapped the regions that saw the largest temperature anomalies in 2023 — places that have warmed so fast that the climate is already testing the limits of human infrastructure and the ability of the natural world to cope.

A warming climate has meant less snow in the northern hemisphere, which is a problem when agriculture depends on melting snow to grow crops. Bloomberg reports on the current snow drought situation.
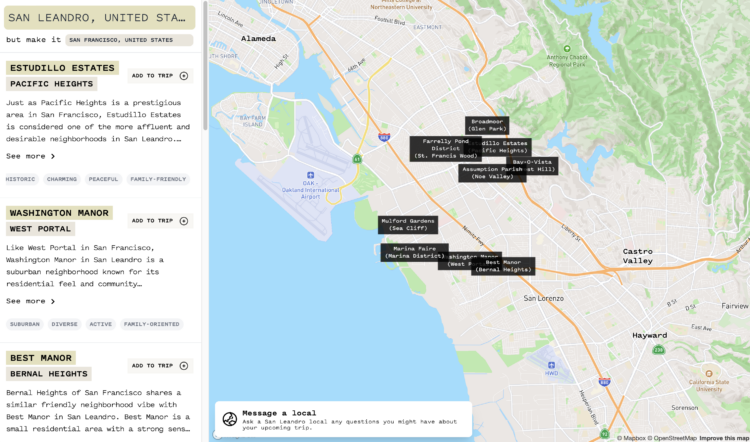
If you’re traveling to a new city, it can be tricky to figure out where things are and what the places are like. However, if you had a tool that set the context of the new city in terms of the neighborhoods in a city you know, you might get a better feel for the new city. Raymond Kennedy made an app (that appears to rely heavily on the OpenAI API) that lets you search the unfamiliar city against the familiar. [via Waxy]
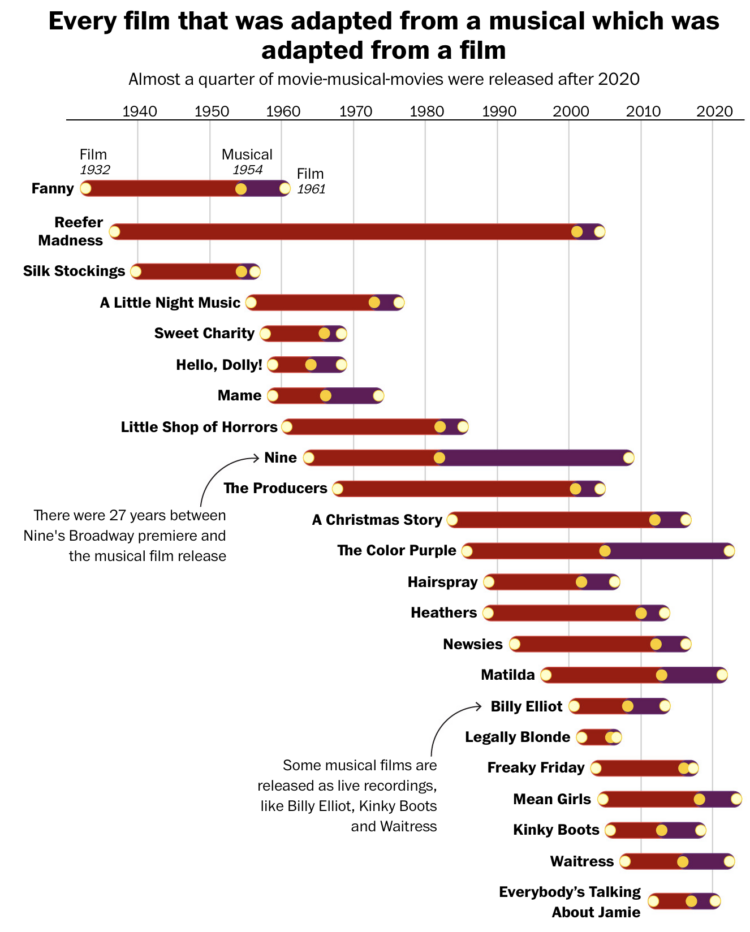
For The Washington Post, Hanna Zakharenko charted all the movies that were adapted from musicals that were adapted from movies. So the above shows the timelines for original movies. Then the musicals that came after. Then the movies again, with songs. Got it.
We often talk about visualization in terms of restrictions and rules, as if you must limit your possibilities to make charts the right way. As you might have guessed, there are other options.
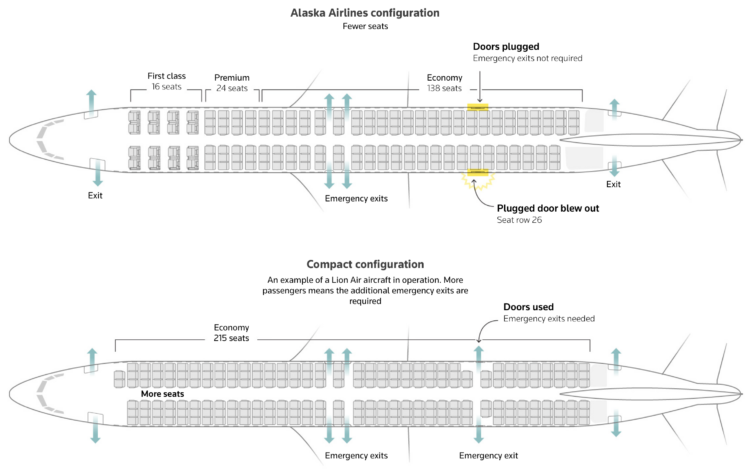
A refrigerator-sized panel popped off a Boeing 737 MAX 9 during the ascent of an Alaska Airlines flight. Reuters illustrates what that panel is for, other airlines with the same configuration, and where they travel.
In the 2000s, if you wanted to make interactive or animated visualization for the web, Flash was the main option. When Flash lost support and fell off the internet, a solid decade of great visualization no longer worked.
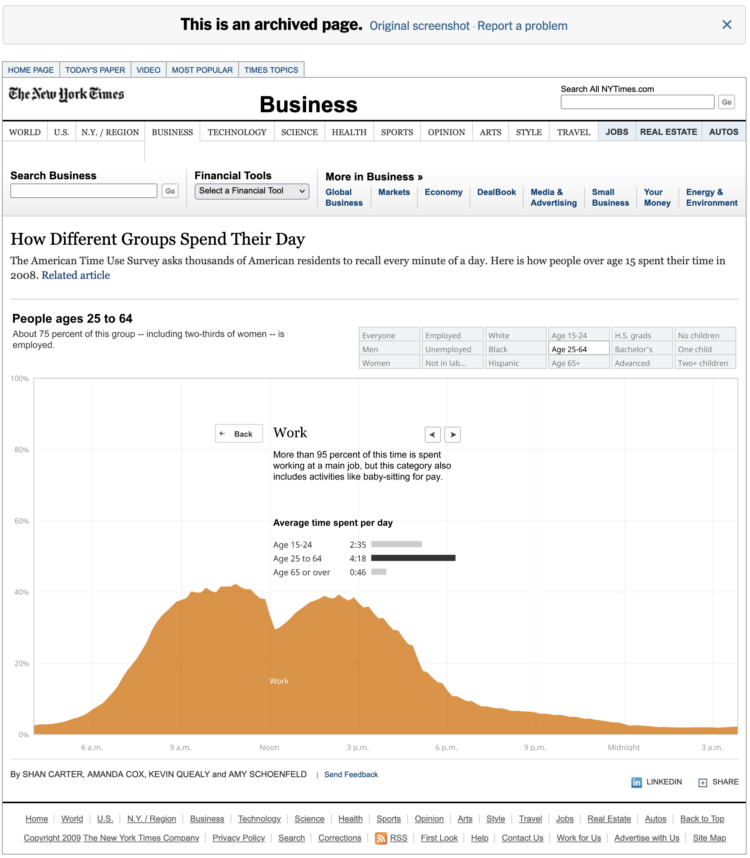
The New York Times has resurrected their archives with a Flash emulator. So pieces that were relegated to static thumbnail images are back. See the box office streamgraph that once upset many, the multi-line chart showing jobless rates for people like you, and the interactive stacked area chart on how people spend their day.
NYT is using the open source Ruffle as their Flash emulator. I hope other news outlets follow. It’s great to see my favorite visualizations working again. [via EagerEyes]

Aaron Koelker used a receipt printer to print a six-foot long map of the Wakulla River in Florida. He outlined his process with Adobe Illustrator and the printer. I kind of want a thermal printer now.
See also: grocery receipt with charts.
The classic coin flip is treated as a fair way to make decisions, assuming an even chance for heads or tails on each flip. However, František Bartoš was curious and recruited friends and colleagues to record over 350,000 flips. There appeared to be a slight bias.
For Scientific American, Shi En Kim reports:
The flipped coins, according to findings in a preprint study posted on arXiv.org, landed with the same side facing upward as before the toss 50.8 percent of the time. The large number of throws allows statisticians to conclude that the nearly 1 percent bias isn’t a fluke. “We can be quite sure there is a bias in coin flips after this data set,” Bartoš says.
There is probably more than one caveat here, but even though there were a lot of flips, they only came from 48 people and the bias varied across flippers.
Of course, if you’re trying to get a call in your favor, maybe try to catch a glimpse of which side is up and choose accordingly. Couldn’t hurt.
There were many AI-based things in 2023. Simon Willison outlined what we learned over the year:
The most surprising thing we’ve learned about LLMs this year is that they’re actually quite easy to build.
Intuitively, one would expect that systems this powerful would take millions of lines of complex code. Instead, it turns out a few hundred lines of Python is genuinely enough to train a basic version!
What matters most is the training data. You need a lot of data to make these things work, and the quantity and quality of the training data appears to be the most important factor in how good the resulting model is.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.









