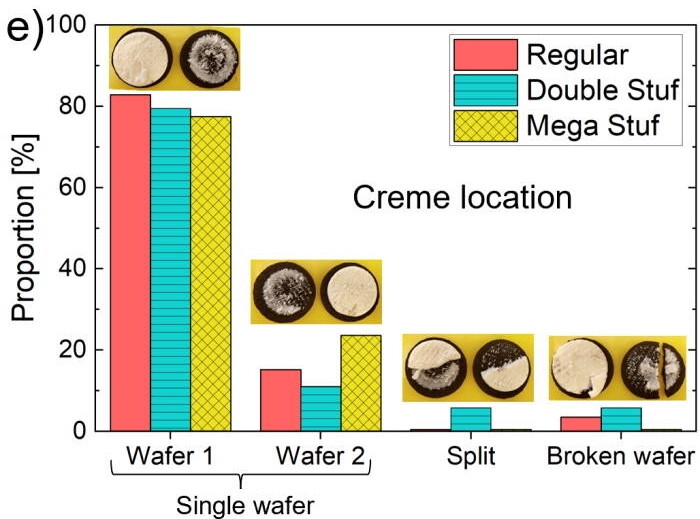
Crystal Owens, Max Fan, John Hart, and Gareth McKinley from Massachusetts Institute of Technology published their research on how the cream in an Oreo behaves when you split the sandwich, in Physics of Fluids:
Using a laboratory rheometer, we measure failure mechanics of the eponymous Oreo’s “creme” and probe the influence of rotation rate, amount of creme, and flavor on the stress–strain curve and postmortem creme distribution. The results typically show adhesive failure, in which nearly all (95%) creme remains on one wafer after failure, and we ascribe this to the production process, as we confirm that the creme-heavy side is uniformly oriented within most of the boxes of Oreos. However, cookies in boxes stored under potentially adverse conditions (higher temperature and humidity) show cohesive failure resulting in the creme dividing between wafer halves after failure. Failure mechanics further classify the creme texture as “mushy.” Finally, we introduce and validate the design of an open-source, three-dimensionally printed Oreometer powered by rubber bands and coins for encouraging higher precision home studies to contribute new discoveries to this incipient field of study.
This is very important. [via kottke]




 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









