
A comic by Marcos Balfagón attaches action to the curve.
A comic by Marcos Balfagón attaches action to the curve.

Every month I collect useful visualization tools and resources to help you work better or more efficiently. Here’s the good stuff for March.
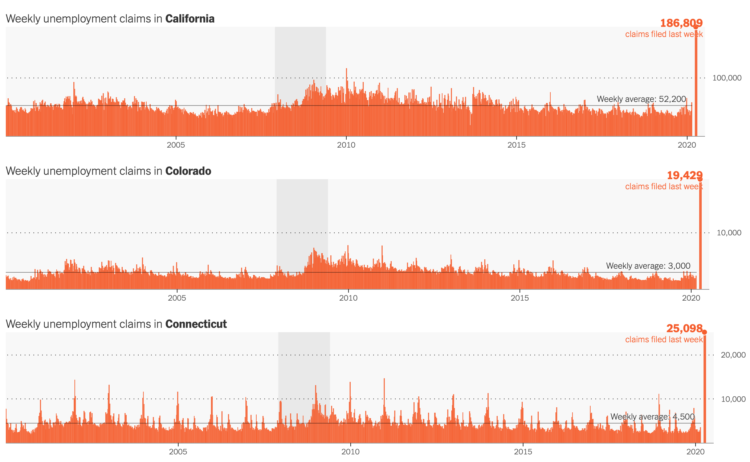
The Department of Labor released the numbers for last week’s unemployment filings. 3.28 million for the country. For The New York Times, Quocktrung Bui and Justin Wolfers show the numbers relative to the past and a breakdown by state:
This downturn is different because it’s a direct result of relatively synchronized government directives that forced millions of stores, schools and government offices to close. It’s as if an economic umpire had blown the whistle to signal the end of playing time, forcing competitors from the economic playing field to recuperate. The result is an unusual downturn in which the first round of job losses will be intensely concentrated into just a few weeks.
You can find the recent data here.
The numbers are fuzzy. You take them at face value, and you end up with fuzzy interpretations. Starting at the end of this month, Johns Hopkins is providing a two-week epidemiology course on understanding these numbers better:
This free Teach-Out is for anyone who has been curious about how we identify and measure outbreaks like the COVID-19 epidemic and wants to understand the epidemiology of these infections.
The COVID-19 epidemic has made many people want to understand the science behind pressing questions like: “How many people have been infected?” “How do we measure who is infected?” “How infectious is the virus?” “What can we do?” Epidemiology has the tools to tell us how to collect and analyze the right data to answer these questions.
Yes.
Wade Fagen-Ulmschneider made a set of interactive charts to track confirmed coronavirus cases. Switch between regions and scales. See the data normalized for population or not. See trends for active cases, confirmed cases, deaths, and recoveries.
Usually this much chartage and menu options would seem overwhelming. But by now, many of us have probably seen enough trackers that we’re ready to shift away from consumption into exploratory mode.
The data behind this tracker, like many others, is from the Johns Hopkins University Center for Systems Science and Engineering (JHU CSSE). They’ve been updating their repository daily on GitHub.
I read and read and read and read. But almost everything I read about is out of my control, so I’m turning more energy towards things that I can control. I’m keeping my distance. Supporting local. Writing. Poking at data. Making charts.
It’s going to get better, and we will get through this.
A chart from Business Insider makes a poor attempt to compare the death rates, by age, for the common flu against Covid-19:
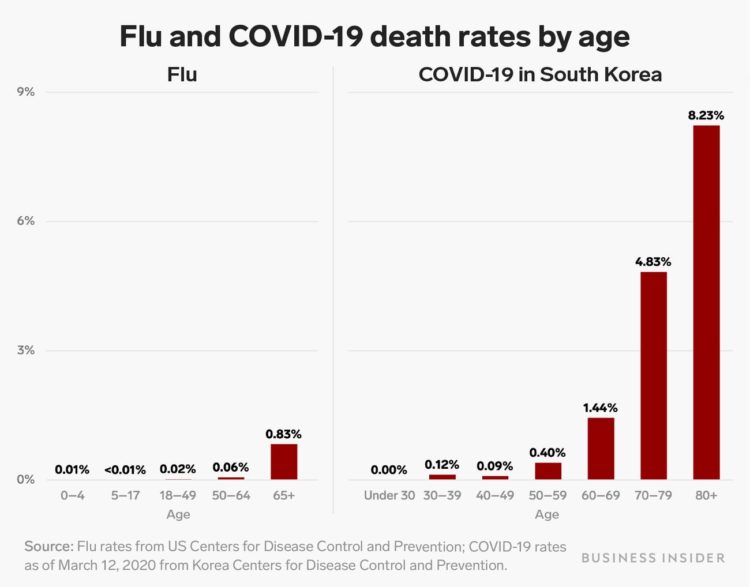
The age groups on the horizontal axes are different, so you can’t make a fair side-by-side comparison. For example, the flu chart has a 50-64 age group. The Covid-19 chart has a 50-59 group and a 60-69 group.
Ann Coulter’s interpretation of the chart might be worse than the chart itself:
For people under 60, coronavirus is LESS dangerous than the seasonal flu: pic.twitter.com/3EFzUSaOVo
— Ann Coulter (@AnnCoulter) March 24, 2020
No.
The values for people under 60, other than for the “under 30” group, are greater for Covid-19 than for the flu. Coulter’s interpretation is wrong no matter which way you cut it. Also, the article that the chart comes from points out the opposite.
I get it. It’s Twitter. There will be mistakes. But at least correct or delete them, instead of dangling it out there for people to spread.
For those making charts, please think about how others will interpret them. These are weird times and we don’t need to add more confusion. For those sharing charts, please think for a second before you put it out there.
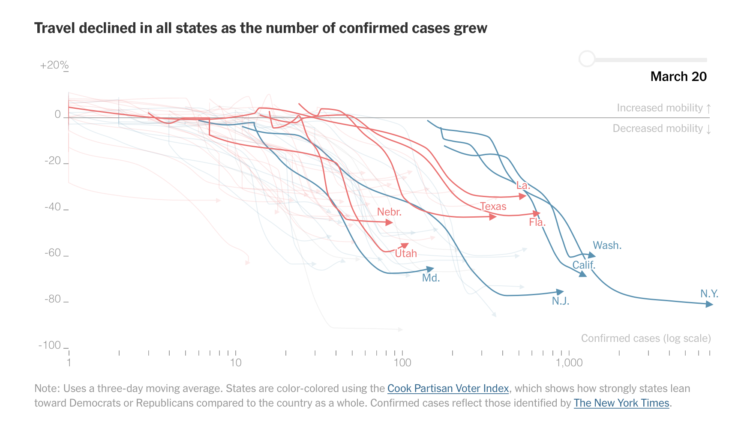
Stuart A. Thompson and Yaryna Serkez for New York Times Opinion on decreasing movement, based on mobile phone data:
The impact of social distancing and work-from-home measures has been captured using data on smartphone movements, an analysis of which was provided to the Times Opinion section by Descartes Labs, a geospatial analysis company.
The data shows how states hit hard by the virus, like New York, California and Washington, have seen travel plummet. But other states with fewer confirmed infections have seen smaller declines, presenting challenges for controlling the spread of the virus.
If you can: stay at home, stay at home, stay at home. Keep going.
As an aside, this is an interesting juxtaposition to privacy concerns over mobile data used for less than honorable purposes. From Descartes Labs, who analyzed the data for NYT:
Location data, as reported by mobile devices, is a powerful resource to understand our world and monitor aggregate change in human behavior in times of crisis. While there are legitimate privacy concerns associated with location data, Coronavirus demonstrates that there are important applications for this data to address some of the more vexing challenges we face in a world where society and economies are more complicated than ever before. Consistent with industry norms, we source data that is de-identified, and we do not use it to identify an individual. All resulting analysis is then statistically aggregated, removing the ability to characterize the behavior of any single device.
I spend 50% of my waking hours washing my hands. I spend the other 50% trying not to touch my face.
David Spiegelhalter on communicating a crisis:
There are some basic principles, which I learnt from John Krebs, former Chair of the Food Standard Agency, who had to deal with many crises. The first thing is that you should be communicating a lot, consistently and with trusted sources. You have to be open and transparent. You have to say what you do know and then you have to say what you don’t know. You have to emphasise, and keep emphasising, the uncertainty, the fact that there is much we don’t know. Then you have to say what you are planning to do and why. Finally, you have to say what people themselves can do, how they should act. The crucial thing to say is that this will change as we learn more.

In a Channel 4 clip, Hugh Montgomery does some back-of-the-napkin math contrasting the normal flu against the coronavirus. Here’s a chart version.
For The Spinoff, Toby Morris illustrates how individuals can break a chain of events:
The good news is, we can do things that will reduce the chances of us spreading the virus. That means we can break these chains and potentially stop hundreds or even thousands of people getting Covid-19. Check out The Spinoff cartoonist Toby Morris’ excellent illustration to understand how individual discipline can have an outsize impact.
Of course infection between people in a community is more complex. Just because one chain is broken doesn’t mean people further down won’t be infected by others in some other way. The goal though is to break as many chains as possible.
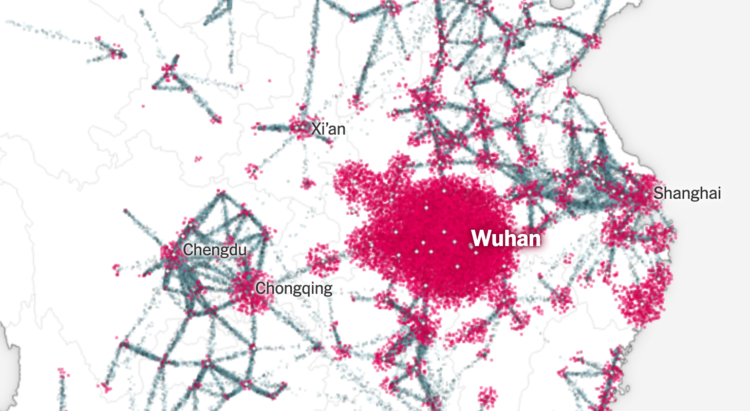
Using a combination of estimates based on cell phone movements and outbreak size, The New York Times shows how the coronavirus started with a few cases and then spread around the world.
The particle flows to represent travel volume from city to city is something else. NYT used a scrollytelling format that starts on a geographic map. You see a few points at first, the virus spreads, and then there’s a transition to an abstract view that looks like a subway map. You end up in the United States with a view of the current estimates.
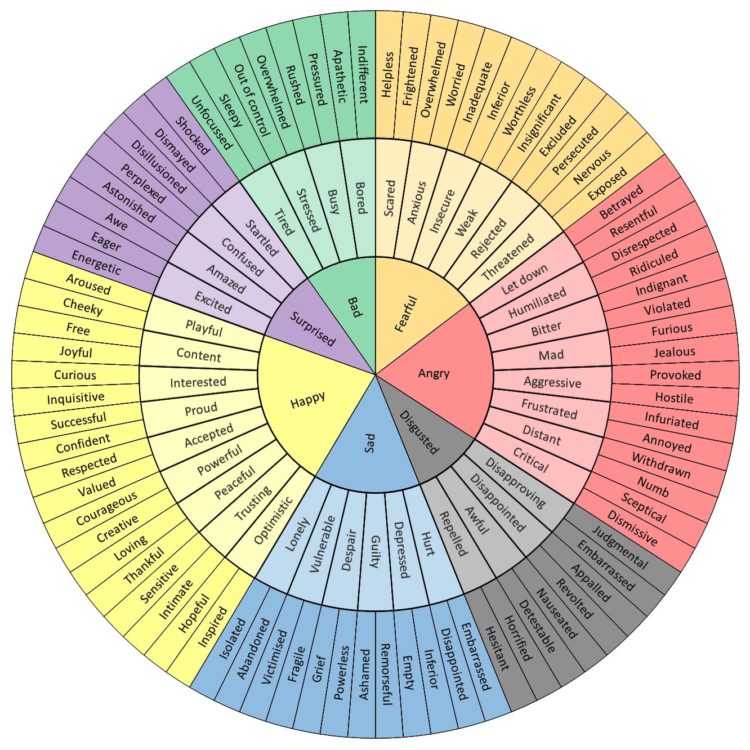
You’re probably feeling a range of emotions these days. It helps if you can express them. This emotional word wheel by Geoffrey Roberts might help:
I work with people who have limited emotional vocabulary and as a result the intensity of their negative emotions and experiences is heightened because they can’t describe their feelings (especially their negative feelings). That’s why this list is heavily focused on negative emotions/ experiences. Being able to clearly identify how we are feeling has been shown to reduce this intensity of experience because it re-engages our rational mind.
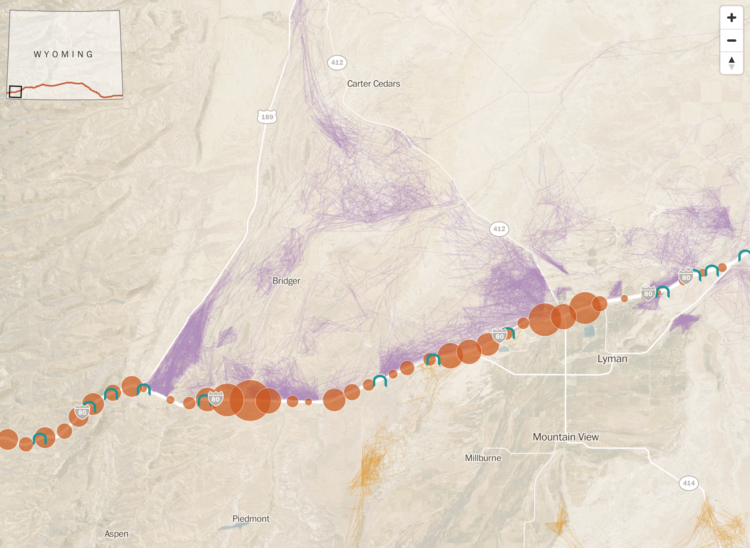
With the climate changing, animals will need to migrate to different areas to live, but that can be a challenge when there is a giant highway blocking the way. The Washington Post looks at how scientists in Wyoming are hoping to clear the path:
“We can’t predict exactly what the impacts of climate change are going to be, or what species are going to be impacted,” said Hall Sawyer, a research biologist at Western Ecosystems Technology. “We do know one fundamental truth: That if we can keep this landscape connected, improve that permeability, they’ll be better off.”
Kurzgesagt, which make videos to explain complex and abstract concepts in an understandable way, explain the coronavirus and what you should do. Spoiler alert: wash your hands and keep your distance.
The entire state of California just went full on stay-at-home. I hope it works.
Vox used a lotion that mimics viruses to demonstrate the power of washing your hands for twenty seconds:
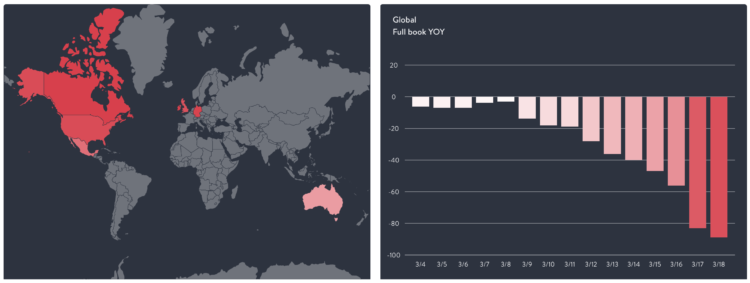
The restaurant industry is taking a big hit right now, as most people are staying put at home. OpenTable provides a downloadable dataset to show how much restaurant dining is down:
This data shows year-over-year seated diners at restaurants on the OpenTable network across all channels: online reservations, phone reservations, and walk-ins. For year-over-year comparisons by day, we compare to the same day of the week from the same week in the previous year. For example, we’d compare Tuesday of week 11 in 2020 to Tuesday of week 11 in 2019. Only states or cities with 50+ restaurants in the sample are included. All restaurants on the OpenTable network in either period are included.
It’s red all the way down. Support your local businesses the best you can.

We don’t know what’s going to happen in the future, but we can look at what we do know and make our best guess.
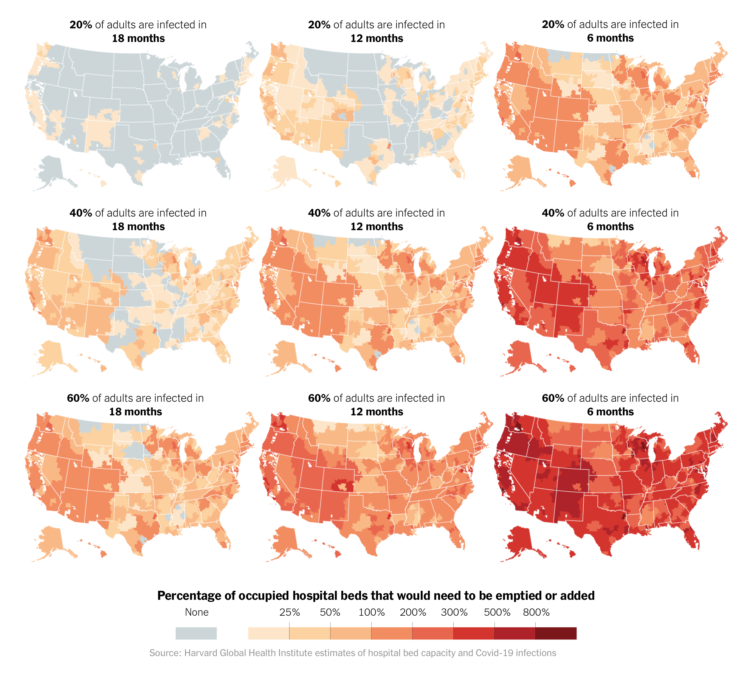
Using estimates from the Harvard Global Health Institute, The Upshot mapped what hospital bed occupancy might look like across the country if we don’t make changes now:
“If we don’t make substantial changes, both in spreading the disease over time and expanding capacity, we’re going to run out of hospital beds,” said Dr. Ashish Jha, the director of the Harvard Global Health Institute, which produced the estimates. “And in that instance, we will not be able to take care of critically ill people, and people will die.”
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.









