
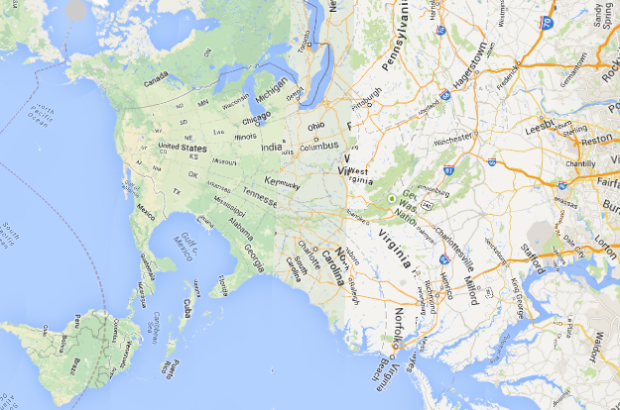
While we’re on the topic of NYC taxi data, Eric Fischer for Mapbox mapped all 187 million trips. Each observation contains the start and end location of a trip, so blue dots represent the former and orange represent the latter. My favorite bit is on the data collection artifacts, such as the map above.
The patterns at JFK and LaGuardia airports show interesting artifacts of the data collection process. Almost all of the trips there must have really begun or ended right at the terminals, but many of them are attributed to the roads leading to and from the airports, where the last good GPS fix must have occurred.
See also the New York Times animated map from several years ago that shows taxi activity during days of the week.
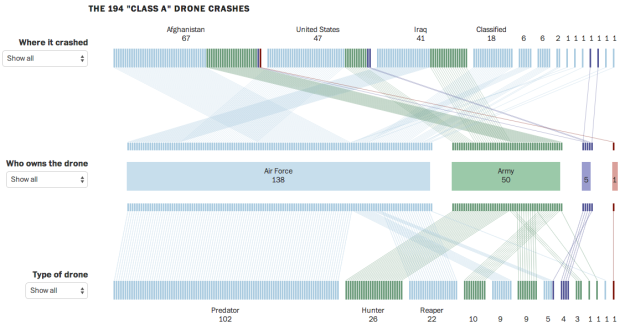
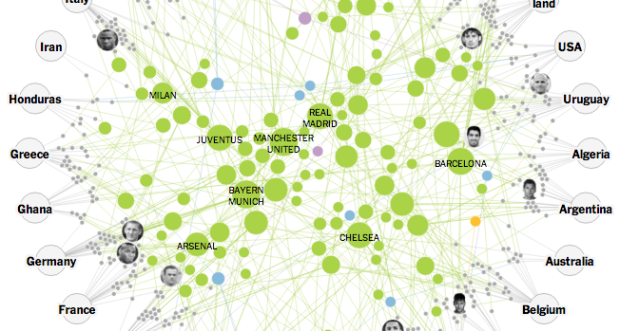
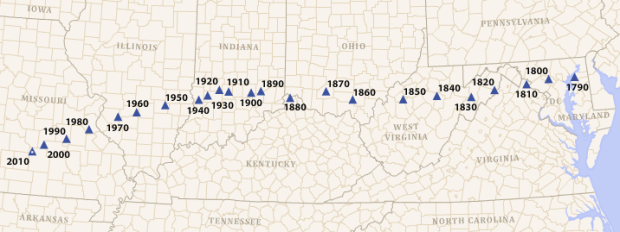

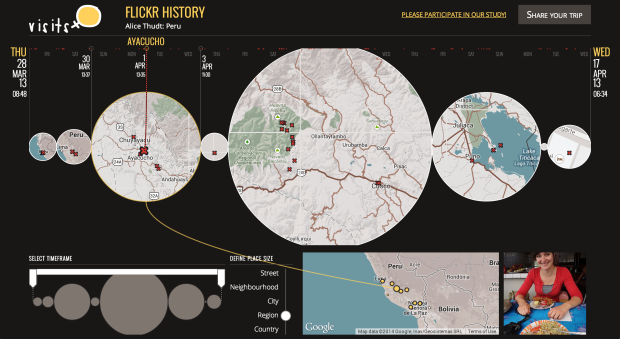
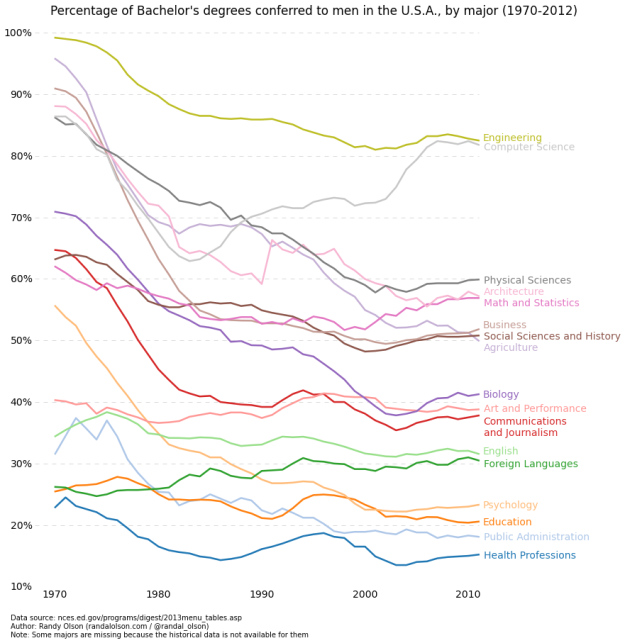

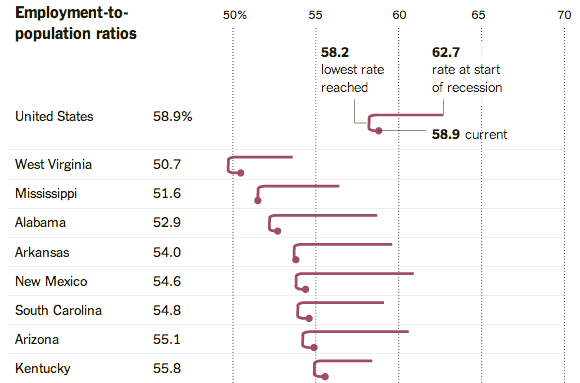



 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









