
Maximum Distance. Minimum Displacement. by Tahir Hemphill explores rappers’ geographic mentions in their lyrics.
Geographic mentions from the complete bodies of work of 12 rappers were extracted using the language analysis database invented by Hemphill — the Rap Almanac. These locations were translated into geographic coordinates, which were then made into points used to plot the movements of an industrial robot arm.
For several minutes at a time, the robot arm drew the paths while holding a light pen producing sculptural forms made with light. Each unique shape represents the global distance travelled by the lyrics in each artist’s career.
The above is the result for Kanye West.









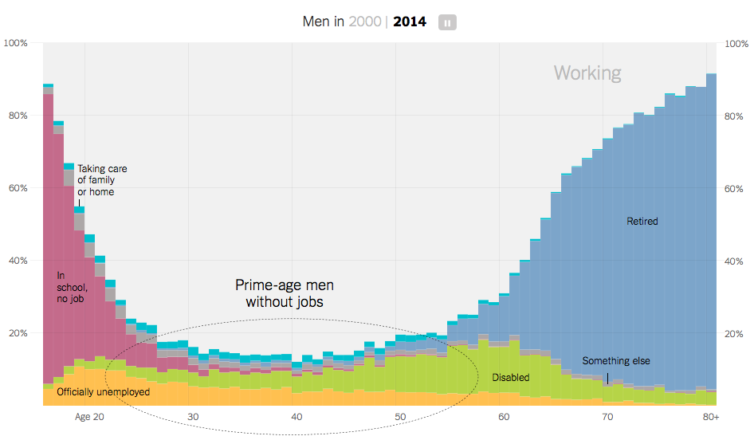
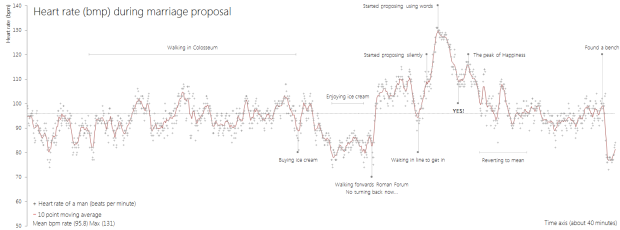


 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









