A handy chart by Andrew M.H. Alexander. Treemap conversion from one gallon, down to a teaspoon.
-
The Upshot has a detailed, chart-filled summary of the shrinking middle class, categorized by age, education, race, and family status.
Read More -

You’ve probably heard about herd immunity by now. Vaccinations help the individual and the community, especially those who are unable to receive vaccinations for various reasons. The Guardian simulated what happens at various vaccination rates.
Luckily, the measles vaccine — administered in the form of the MMR for measles, mumps and rubella — is very effective. If delivered fully (two doses), it will protect 99% of people against the disease. But, like all vaccines, it’s not perfect: 1% of cases are likely to result in vaccine failure, meaning recipients won’t develop an immune response to the given disease, leaving them vulnerable. Even with perfect vaccination, one of every 100 people would be susceptible to measles, but that’s much better than the alternative.
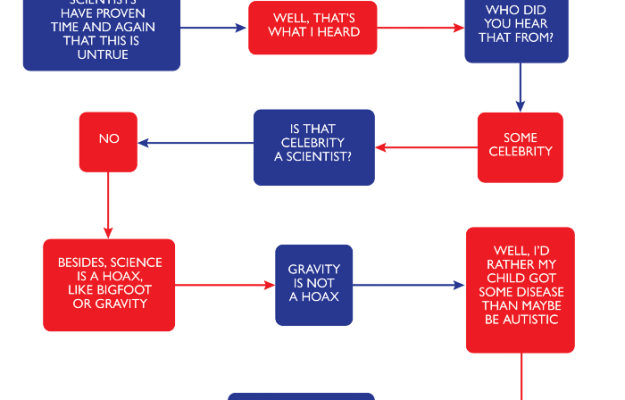
If you’re still unsure, please consult this flowchart to decide.
-
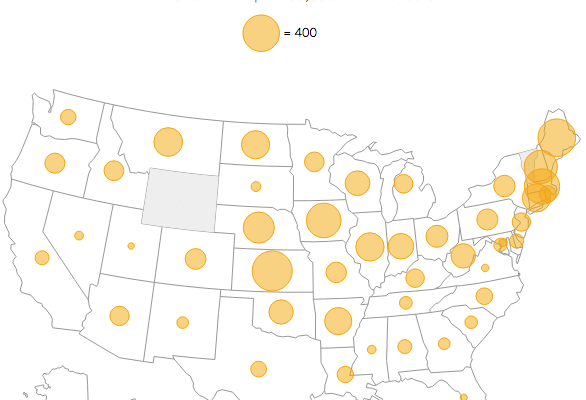
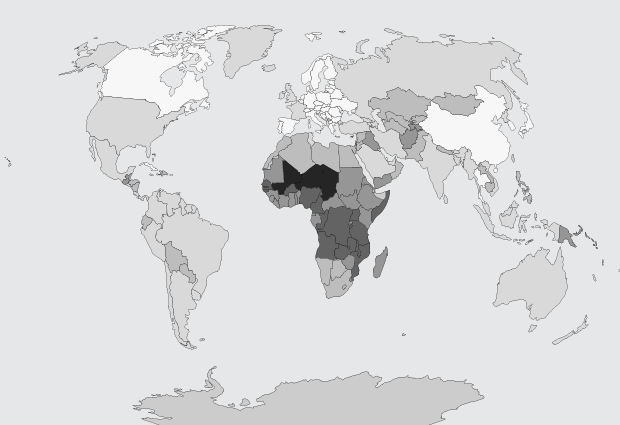
There are an estimated 60 million more men than women on this planet, based on data from World Bank. David Bauer takes a look at the places where the male majority is largest.
Read More -
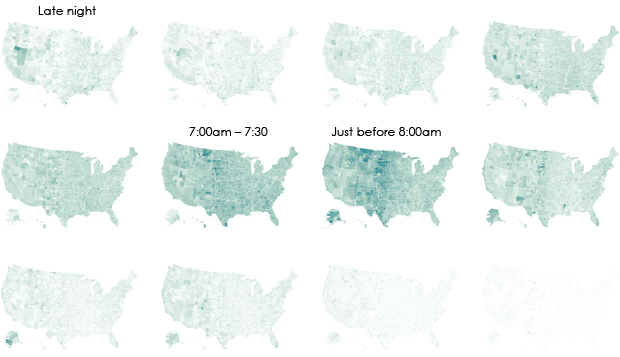
We don’t all start our work days at the same time, despite what morning rush hour might have you think.
-

In Soundweaving, Zsanett Szirmay used embroidery as a score to feed into a music box. Each stitching square is a punch hole, and because of the repeating patterns in “embroidered shirts and pillows from the Transylvanian Bukovina,” the results aren’t so farfetched as musical notes.
Read More -

Pew Research Center released a report that compares the public and scientists’ views on science and society.
On some things, such as the space station, fracking, and bioengineered fuel, U.S. adults and scientists a part of the American Association for the Advancement of Science share similar sentiments. On other issues, such as genetically modified foods, animals in research, and climate change, there are big differences.
-
Here’s a fun searchable map from the New York Times. Enter a street’s name, and you can see how many other streets have the same name in other states. Based on Zillow data, you also get a quick comparison of estimated worth of houses on your street versus homes with the same street name but different suffix.
Read More -
Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes. Yes.
-

It’s a common belief that if someone has a medical condition, a patient can take a treatment and the condition gets better or goes away. That is, improvement is directly related to intake. However, as it turns out, there’s often a good chance the patient would have gotten better without the treatment. There’s also a chance a treatment does nothing.
Austin Frakt and Aaron E. Carroll for the Upshot describe these chances through a metric called number needed to treat, or N.N.T. The simple animations throughout the article provide a great dose of perspective to the odds.
-
A data-centric look at New England Patriots fumble rates at home made the rounds this week. The most cited tidbit was that there is only a 1 in 16,233 chance that the Patriots achieved the lower rate via randomness. Therefore, the Patriots must have cheated. Gregory J. Matthews and Michael Lopez explain, finding by finding, why the results from Sharp Football Analysis are suspect.
Even if you’re not into football, read it for the statistics lesson.
Read More -

I don’t know exactly how much data NASA has in the bank, but I think it’s a lot. Explained in the video below, they estimated the age of ice layers in Greenland by flying a plane over the Greenland Ice Sheet and pulsing radar to gather information.
Read More -
Celebrating the 100th year of the National Geographic cartographic department, they provide a truncated roundup of the thousands of maps they’ve made over the past century. I liked this tidbit about the Germany map above:
Our maps haven’t just chronicled history; they’ve made it. General Dwight D. Eisenhower carried our map of Germany during his 1945 offensive. When a B-17 carrying Admiral Chester Nimitz got lost in a rainstorm, the pilot landed safely using the Society’s map of the Pacific war theater. The map, Nimitz later wrote Gilbert H. Grosvenor, “lent an unexpected but most welcome helping hand.”
It’s true. Maps, even on paper, can be useful.
-

John Edmark made some pretty things.
Read More -
Choropleth Maps and Shapefiles in R
Fill those empty polygons with color, based on shapefile or external data.
-

Seth Stephens-Davidowitz continues with his Google search data-related op-eds for the New York Times. This time he looks at the insecurities in sex, based on the search volume of various phrases.
Interesting. But preface the results with a big fat question of sample population before you make too many conclusions.
For example, a straightforward conclusion from the above graphic is that boyfriends avoid sex way more than girlfriends. That seems off. Could it be that boyfriends avoiding sex confuses the girlfriends more than the other way around, thus making it more likely for girlfriends to search?
-
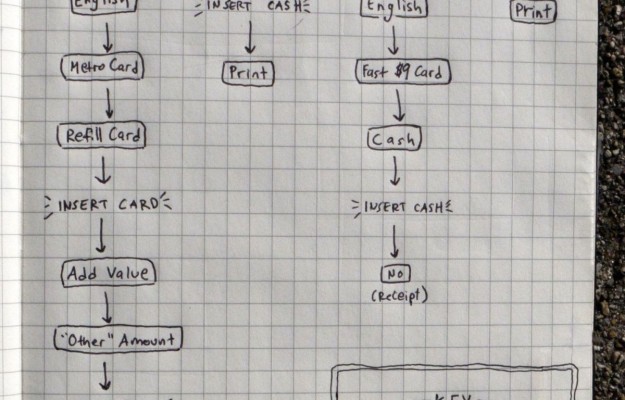
The process to purchase a MetroCard for the New York Subway is different from the process to purchase tickets for the Bay Area Rapid Transit in San Francisco. From the flowchart above by Aaron Reiss, it’s clear that it takes a lot more screen touches to get a MetroCard, but that’s only part of the story. The interesting part is why the two systems’ machines are so different. Different timing means different goals.


Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









