I’m thankful for the opportunity I had to work at Google. I learned more than I thought I would. I’ll miss the free food. I’ll miss the occasional massage. I’ll miss the authors, politicians, and celebrities that come to speak or perform. I’ll miss early chances to play with cool toys before they’re released to the public. Most of all, I’ll miss working with the incredibly smart and talented people I got to know there. But I won’t miss a design philosophy that lives or dies strictly by the sword of data.
I feel like I’ve been hearing a lot of this type of stuff recently. Just yesterday, while watching NBA playoff commentary, someone stated that future Detroit Lions quarterback, Matthew Stafford, had something like a 1 in 4 chance of success in the NFL. Charles Barkeley replied that sometimes you gotta forget about stats and just go, or something to that effect. Oddly enough, I agree.
[via TechCrunch]
UPDATE: Kevin Fox, (formerly) senior user experience design lead at Google, responded to Bowman’s post: “I don’t think Google had to be a bad fit for you, but that you were put in to the wrong role.” [Thanks, David]
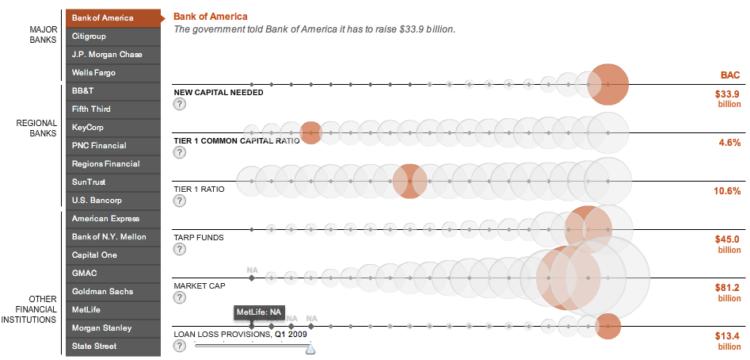
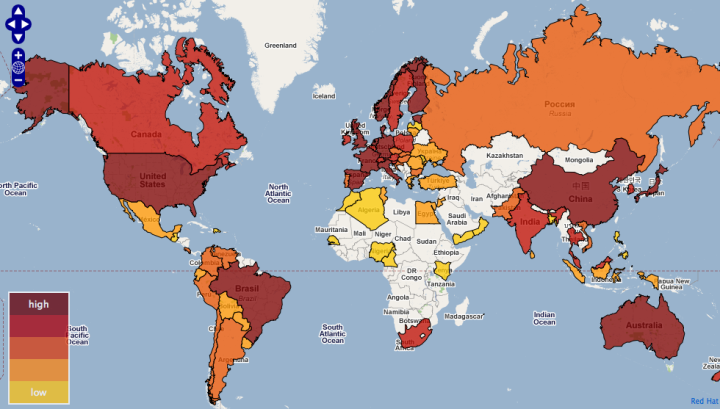

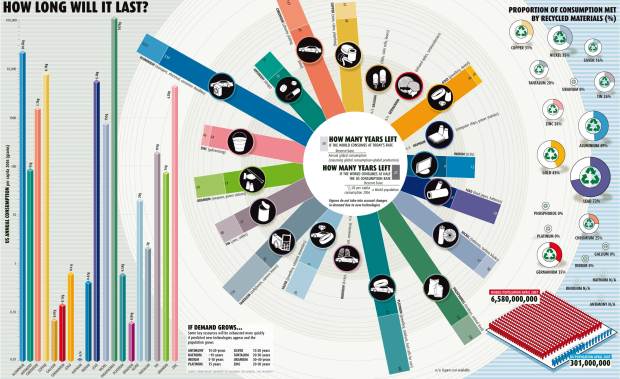
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)










{kind=link}