For The Atlantic, Ian Bogost on communicating complex ideas to an audience:
One thing you learn when writing for an audience outside your expertise is that, contrary to the assumption that people might prefer the easiest answers, they are all thoughtful and curious about topics of every kind. After all, people have areas in their own lives in which they are the experts. Everyone is capable of deep understanding.
Up to a point, though: People are also busy, and they need you to help them understand why they should care. Doing that work—showing someone why a topic you know a lot about is interesting and important—is not “dumb”; it’s smart. Especially if, in the next breath, you’re also intoning about how important that knowledge is, as academics sometimes do. If information is vital to human flourishing but withheld by experts, then those experts are either overestimating its importance or hoarding it.
I struggled with this during my first year of graduate school, because it took a while to get out of my own head and imagine myself as a reader. Or, in the case of that first-year regression analysis course, I was supposed to imagine a policymaker on a tight schedule.
I would crunch numbers or whatever and write reports. My professor told me I had to do a better job explaining the meaning behind the numbers. How should a non-statistician interpret these results? It was my job as the statistician to explain.
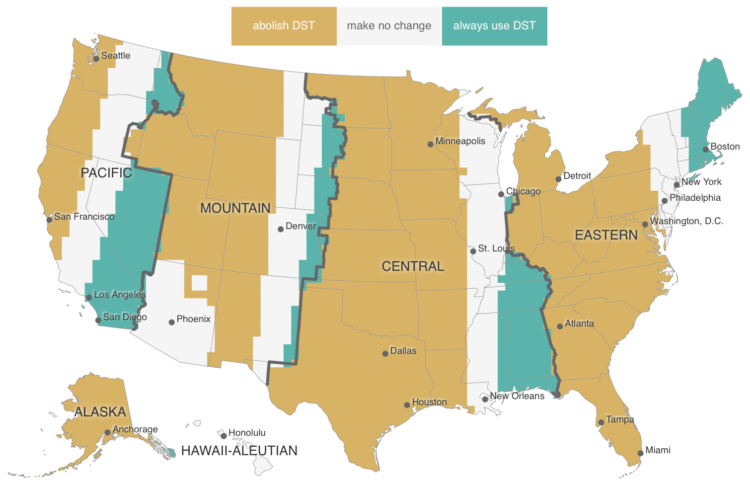

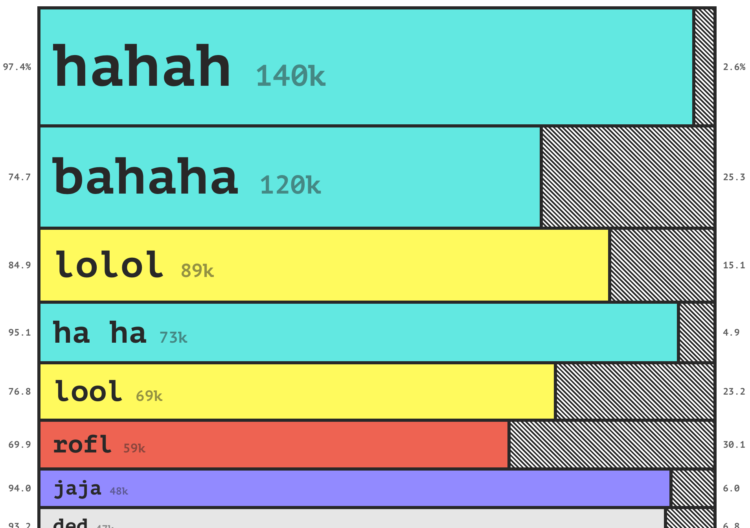

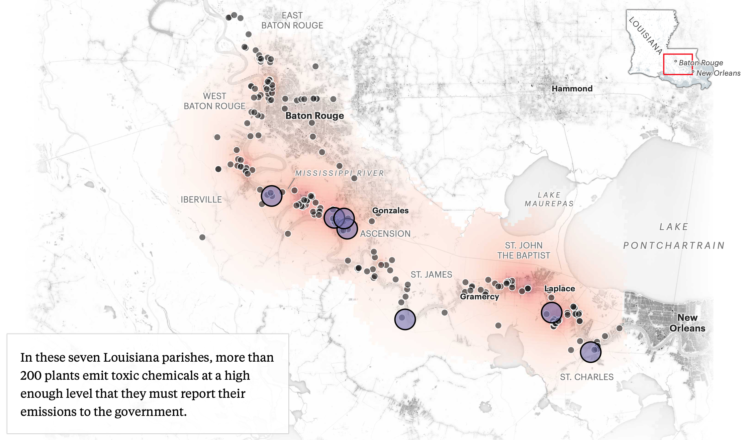

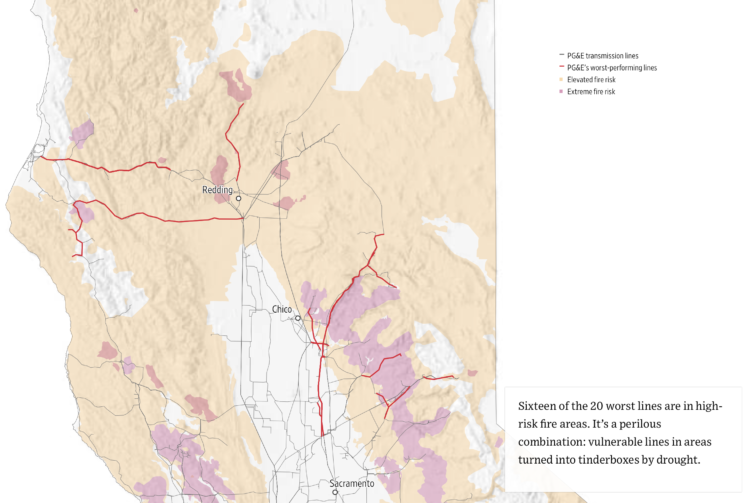

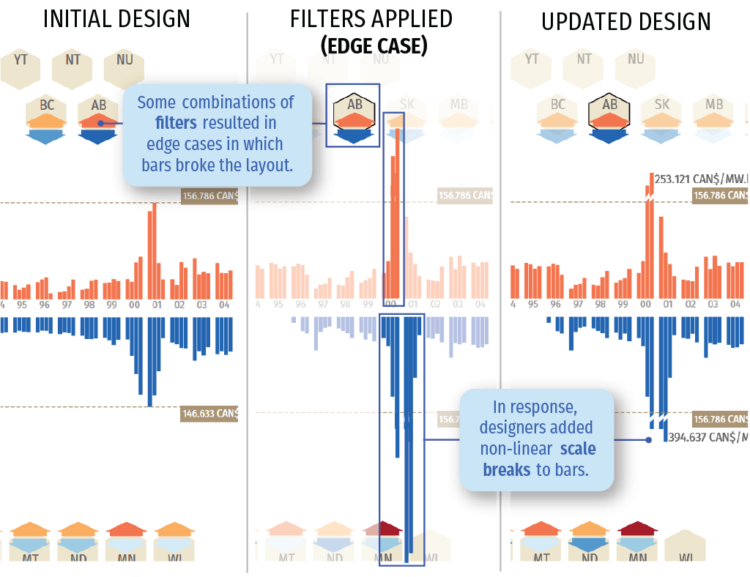
 Charts can reveal truths that we never would see otherwise, but they can also be misused to show us something in the data that doesn’t reflect reality.
Charts can reveal truths that we never would see otherwise, but they can also be misused to show us something in the data that doesn’t reflect reality. 



 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









