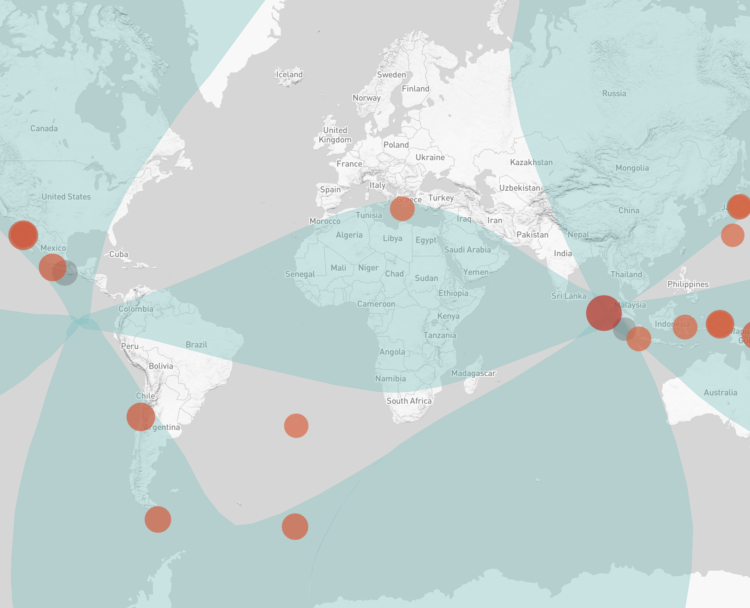
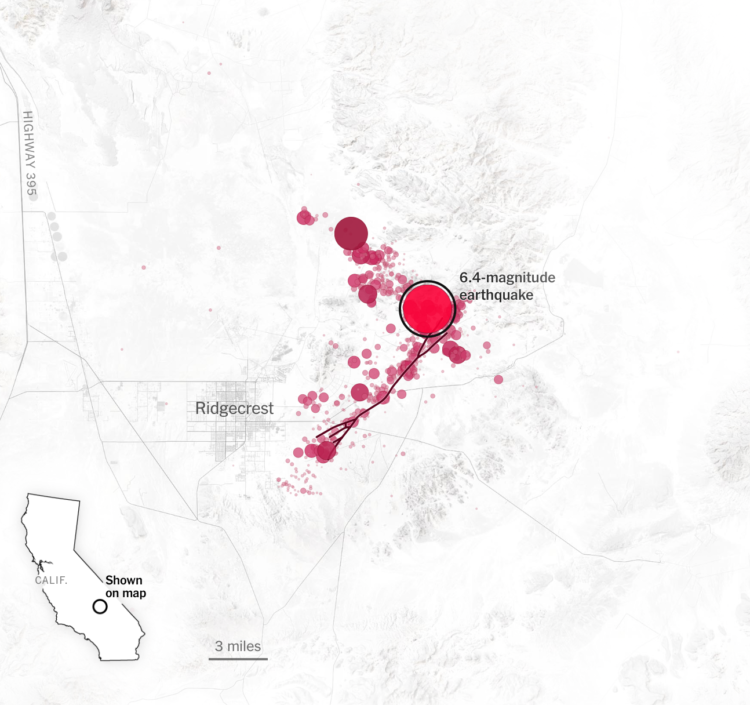
Speaking of earthquakes, Will Chase looked back at a 2012 earthquake in Sumatra that triggered not only a bunch of small ones in the vicinity, but other large ones around the world:
In the ten days following the Sumatra mainshock, 44 earthquakes M5.5+ were recorded. The statistics were clear: this nine-fold increase was highly significant, and most researchers agreed the likely explanation was remote triggering by the M8.6 Sumatra earthquake. This massive triggering of large earthquakes was unprecedented, and many wondered if the strike-slip mechanism at such a large magnitude was a unique combination that led to this outsized response.






 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









