The Bureau of Labor Statistics released monthly jobs data, but after the firing last month, some might be wondering how much we can trust future BLS data. For the New York Times, Ben Casselman asked economists how they’re feeling these days, who mostly said that the data can still be trusted.
In any case, Ms. Groshen and other experts said, even a commissioner with ill intentions would not be able to meddle with the data, at least not in the short run and not without anyone’s noticing. The monthly jobs report is produced on a tight schedule using a highly automated and decentralized process. Most of the data that underlies the monthly payroll figure is reported directly by companies through an electronic system that is subject to strict access limitations. The commissioner, who is the agency’s only political appointee, does not have access to the numbers until they have been made final.
“There’s not like one person in a room who can manipulate things,” said Aaron Sojourner, an economist at the W.E. Upjohn Institute for Employment Research. “There are safeguards in place.”
No sharpies allowed.


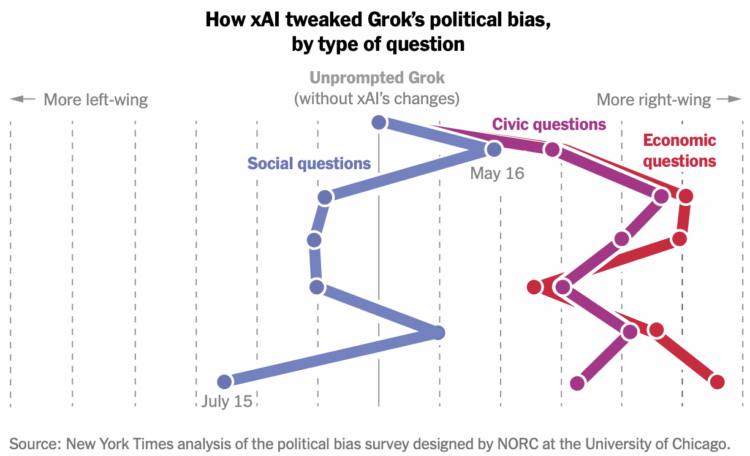
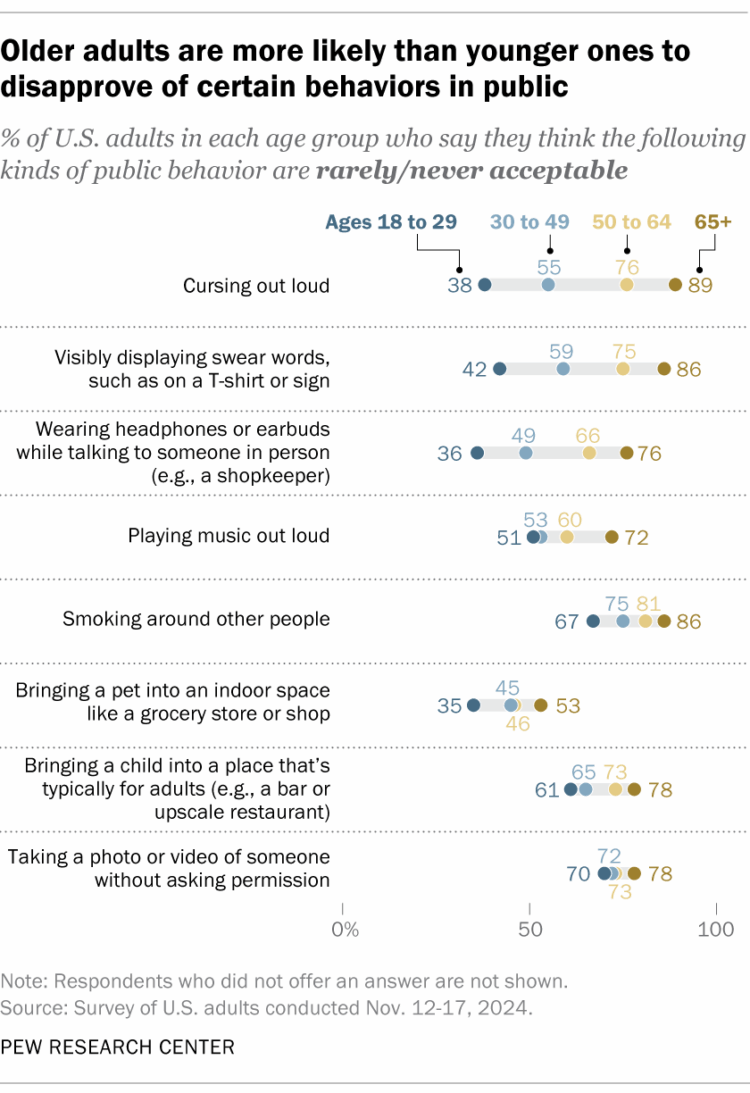



 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









