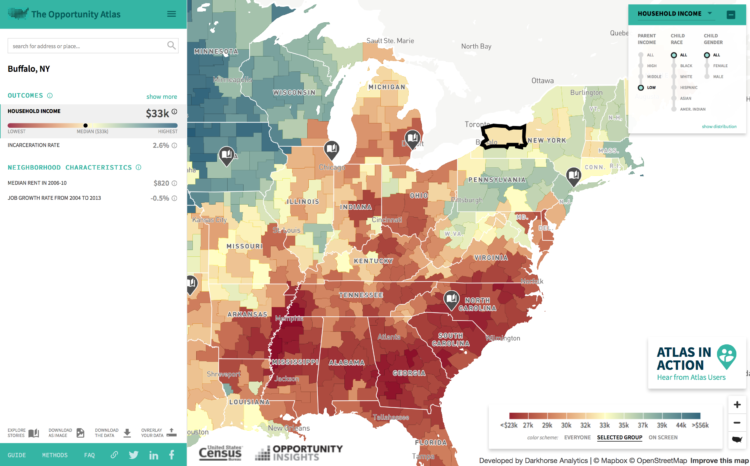
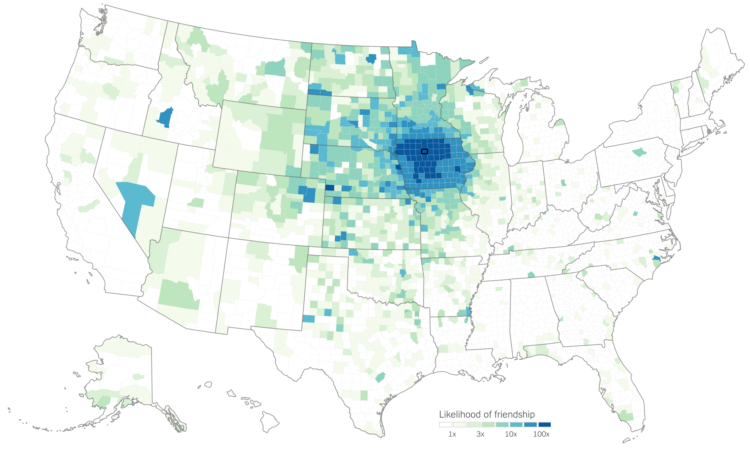
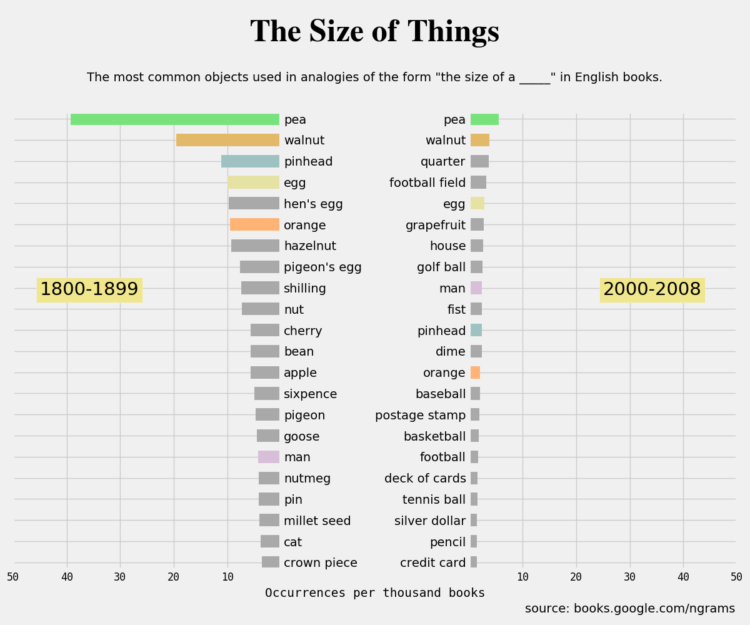
Opportunity Atlas, a collaboration between Opportunity Insights and the Census Bureau, is the product of ongoing research on the demographics of people, based on the neighborhood they grew up in.
The Opportunity Atlas provides data on children’s outcomes in adulthood for every Census tract in the United States through an interactive map providing detailed research on the roots of these outcomes, such as poverty and incarceration rate, back to the neighborhoods in which children grew up. This tool will enable policy makers, practitioners, and the public the unprecedented ability to look within their city to understand better where opportunity exists and how each neighborhood shapes a child’s future economic and educational success.
The map application was developed by Darkhorse Analytics. Zoom in to an area of interest, subset on demographics such as income level, race, and gender, and see how the people who grew up in those areas fared later in life. You can also download the tract-level data to look for yourself.




 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









