A note on a pack of Skittles reads, “No two rainbows are the…
Statistics
More than mean, median, and mode.
-

How many Skittles packs before finding identical ones?
-

Game of Thrones death predictor
Monica Ramirez tried her hand with modeling deaths on Game of Thrones and…
-
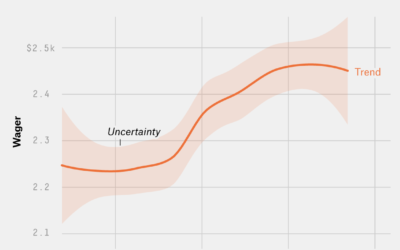
Playing the odds for record-breaking Jeopardy! wins
James Holzhauer is the new hotness on Jeopardy! with Daily Double hunting, big…
-
When bad data leads to a disappearing neighborhood
Caitlin Dewey for OneZero describes the case of the Fruit Belt neighborhood in…
-
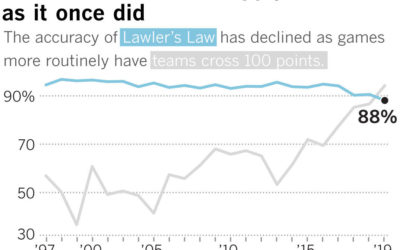
Does the first to 100 points usually win in the NBA?
Los Angeles Clippers commentator Ralph Lawler has a saying: “First to 100 wins.…
-
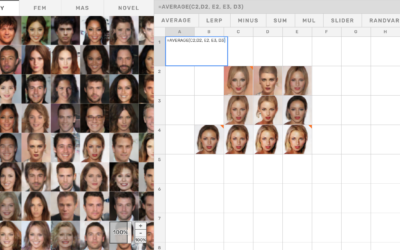
Explore generative models and latent space with a simple spreadsheet interface
Generative models can seem like a magic box where you plug in observed…
-
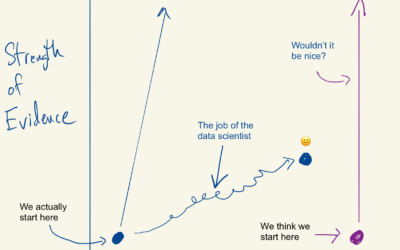
Exploring data to form better questions
Feeding off the words of John Tukey, Roger Peng proposes a search for…
-
Facial recognition machine for $60
For The New York Times, Sahil Chinoy on privacy and how easy it…
-
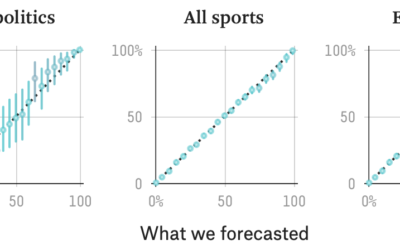
FiveThirtyEight evaluates their forecasts
FiveThirtyEight uses forecasts to attach probabilities to politics and sports, and they get…
-
Finding context for the data
Context makes data useful. Without it, it’s easy to get lost in numbers…
-
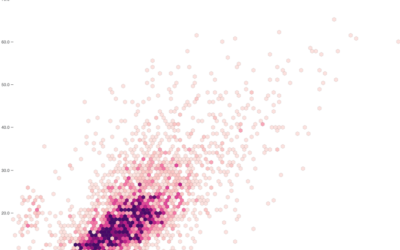
Census data downloader to reformat for humans
There is a lot of Census data. You can grab most of the…
-
Data for 200M traffic stop records
The Stanford Open Policing Project just released a dataset for police traffic stops…
-
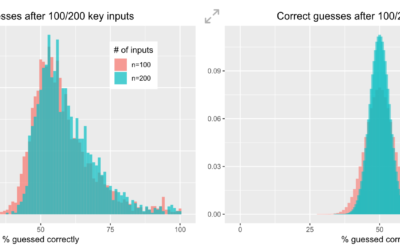
A game to test your ability to pick random numbers
Compared to a computer’s pseudo-random number generator, we are not good at picking…
-
Case of the 500-mile email
Trey Harris, a previous tech administrator for a university, tells the story of…
-
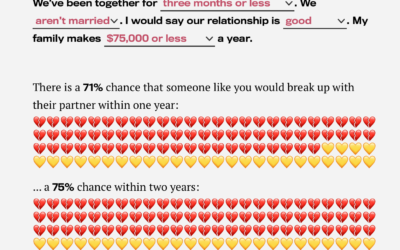
Probability you will break up with your partner
Rosenfeld, et al. from Stanford University ran a survey in 2009 for a…
-
Data-driven porn
Gustavo Turner for Logic on his experiences covering the porn industry and the…
-
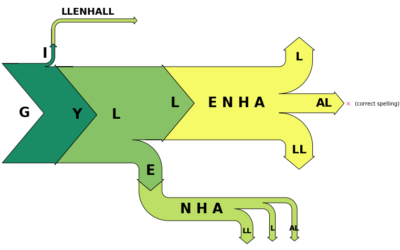
Looking for common misspellings
Some words are harder to spell than others, and on the internet, sometimes…
-
When geolocation makes everyone think you stole their phone
People show up unannounced at John and his mother Ann’s home in South…
-
No such thing as raw data
Nick Barrowman on the myth of raw data:
Assumptions inevitably find their way… -
Fake internet
Max Read for New York Magazine describes the fake-ness of internet through the…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









