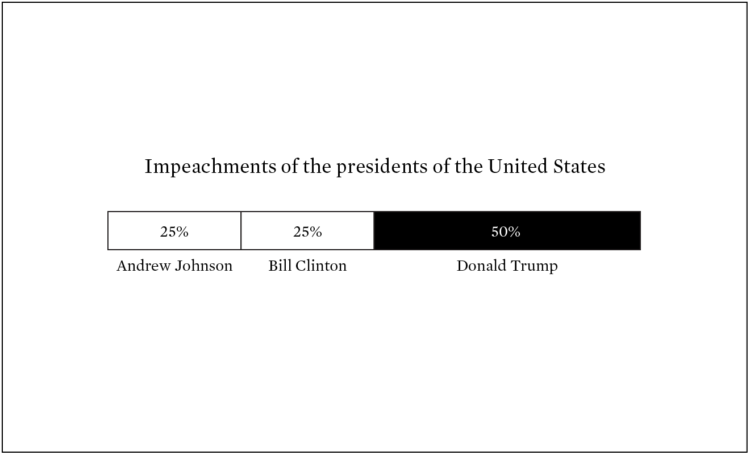
-
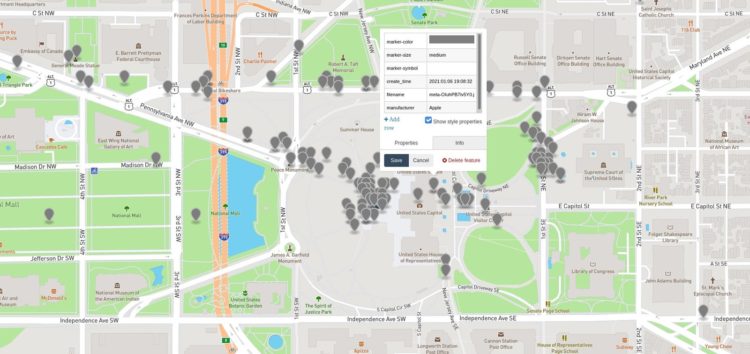
Just before the social network Parler went down, a researcher who goes by the Twitter username @donk_enby scraped 56.7 terabytes of data from the site via a less-than-secure API. Motherboard reports on what some researchers are doing with the data:
One technologist took the scraped Parler data, took every file that had GPS coordinates included within it, formatted that information into JSON, and plotted those onto a map. The technologist then shared screenshots of their map with Motherboard, showing Parler posts originating from various countries, and then the United States, and finally in or around the Capitol itself. In other words, they were able to show that Parler users were posting material from the Capitol on the day of the rioting, and can now go back into the rest of the Parler data to retrieve specific material from that time.
I’ve only seen some quick maps so far, but I imagine there’s much more to come in terms of closer analysis and visualization.
-
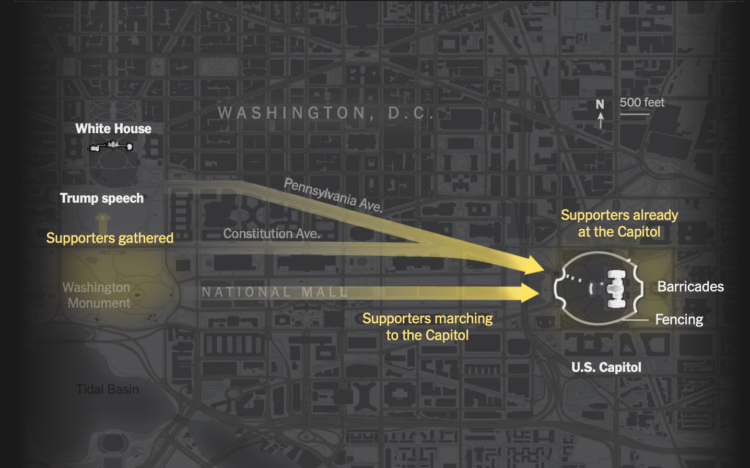
The New York Times outlined the minutes from the speech leading to the mob at the Capitol. By now you’ve probably seen the videos and pictures and have an idea of what happened. But the timeline of events both inside and outside of the building really underscores how much worse it could’ve been.
-
For The Atlantic, Dani Alexis Ryskamp compares the financials of The Simpsons against present day medians, arguing that the fictional family’s lifestyle is no longer attainable:
The purchasing power of Homer’s paycheck, moreover, has shrunk dramatically. The median house costs 2.4 times what it did in the mid-’90s. Health-care expenses for one person are three times what they were 25 years ago. The median tuition for a four-year college is 1.8 times what it was then. In today’s world, Marge would have to get a job too. But even then, they would struggle. Inflation and stagnant wages have led to a rise in two-income households, but to an erosion of economic stability for the people who occupy them.
Someone should take this a step further and look at distributions and time series to show the shift, with The Simpsons as baseline.
-

Last year, around the time when people were baking a lot of things, Sarah Robinson used machine learning to find a recipe for a “cakie”:
Like many people, I’ve been entertaining myself at home by baking a ton and talking about my sourdough starter as if it were a real person. I’m pretty good at following recipes, but I decided I wanted to take things one step further and understand the science behind what differentiates a cake from a bread or a cookie. I also like machine learning so I thought: what if I could combine it with baking??!
Robinson provides the final recipe at the end, so first, I need to try this recipe. Second, what other foods and beverages can this apply to?
-

Natalie Wolchover for Quanta Magazine asked several physicists what a particle is. She came away with several points of view. For example, the particle as a “irreducible representation of a group”:
It’s the standard deep answer of people in the know: Particles are “representations” of “symmetry groups,” which are sets of transformations that can be done to objects.
Take, for example, an equilateral triangle. Rotating it by 120 or 240 degrees, or reflecting it across the line from each corner to the midpoint of the opposite side, or doing nothing, all leave the triangle looking the same as before. These six symmetries form a group. The group can be expressed as a set of mathematical matrices — arrays of numbers that, when multiplied by coordinates of an equilateral triangle, return the same coordinates. Such a set of matrices is a “representation” of the symmetry group.
Oh boy. A lot of this was over my head, as I nearly failed physics in college, but the various explanations with basic diagrams taught me a few new things.
-
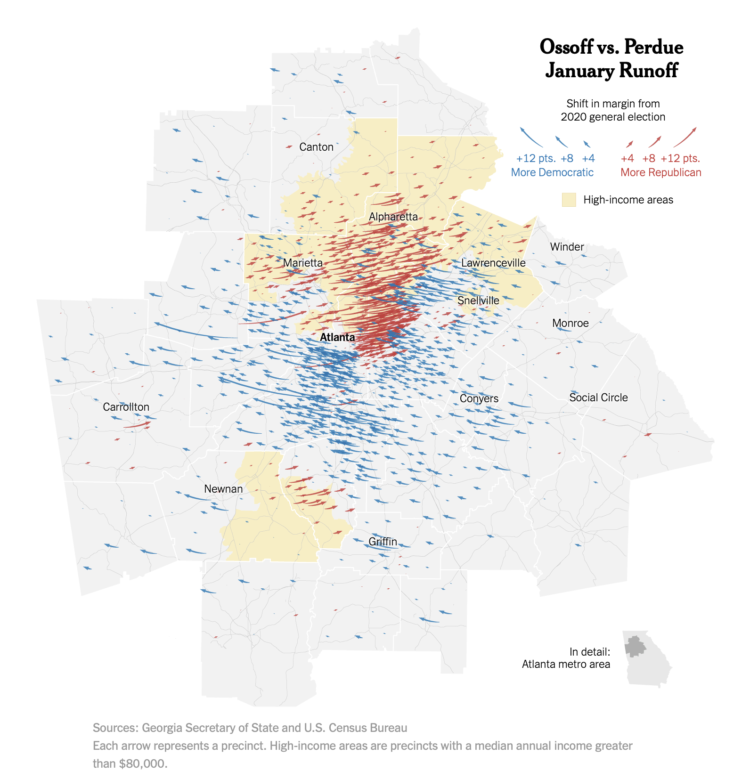
For NYT’s The Upshot, Nate Cohn explains how Warnock and Ossoff won Georgia. The accompanying map by Charlie Smart provides a clear picture of swooping arrows that show the shifts from the general election to the runoff.
-
Members Only
I’m not one for new year’s resolutions, but this year seems different and requires some goals.
-
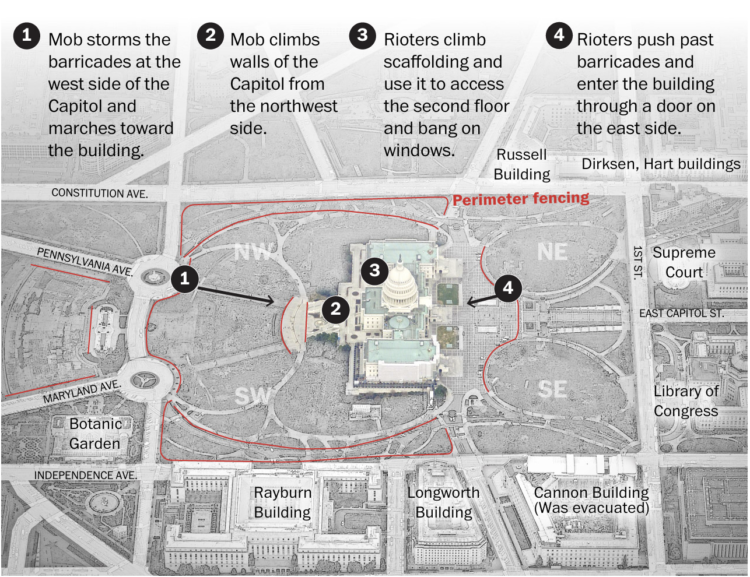
The Washington Post pieced together video footage from multiple sources for a timeline of the events. Terrible.
-

OpenAI trained a neural network that they call DALL·E with a dataset of text and image pairs. So now the neural network can take text input and output random combinations of descriptors and objects, like a purse in the style of Rubik’s cube or a teapot imitating Pikachu.
-

The brickr package in R by Ryan Timpe takes an image, converts it to a mosaic, and then provides a piece list and instructions for the build. While not officially affiliated with the LEGO group, Timpe is a data scientist for LEGO, so it’s probably as close as you’re going to get to real deal.
Timpe made a package a couple of years back, but when I went to use it, the link was broken and I assumed it was defunct. This is a nice surprise.
My kids are deep into LEGO these days. We just finished watching the LEGO Masters show. I have LEGO minifigures on my office wall. I’m definitely making use of this.
-

State population dictates the number of seats in the House of Representatives, so ideally, the decennial Census counts everyone and power is fairly distributed. On the surface, that seems straightforward? For NPR, Connie Jin and Hansi Lo Wang explain with a cat comic.
Because cats.
See also the cat guide on spotting misinformation.
-

The New York Times measured pollution exposure during the day for two kids who live in New Delhi. Usually just described in terms of micrograms of particulate matter, the piece puts in more effort to give a feel for each person’s day-to-day. Side-by-side video along with a scrolling line chart provide a clear contrast between the two lives.
-

Ash Ngu for ProPublica and Sophie Cocke for Honolulu Star-Advertiser show the harm of building seawalls on Hawaii’s beaches. The walls protect luxury beachfront properties, but they have been built through administrative loopholes and destroy beaches, which are owned by the public.
I like the combination of video footage and map, providing a scroll along the coastline. It provides an anchor for where you are and what you’re looking at.
-

Last year, in 2019, my main goals for FlowingData and work were to stay focused and make charts. I was satisfied with my progress, and for 2020, I had hoped to step that up with more depth and more play.
But you know what happened. The year was challenging for many reasons, and it was hard to concentrate or to think of much else other than the day’s current events.
I’m lucky to be able to work from home though, and I am thankful for that. So FD was able to roll on.
As I do every year, I like to bookend with an annual review, so here we go.
Read More -

The New York Times reconstructed the night. Based on a collection of court documents, ballistics reports, body camera footage, and interviews, they built a 3-D model of the scene depicting what appears to be an unorganized and unexpected raid.
-
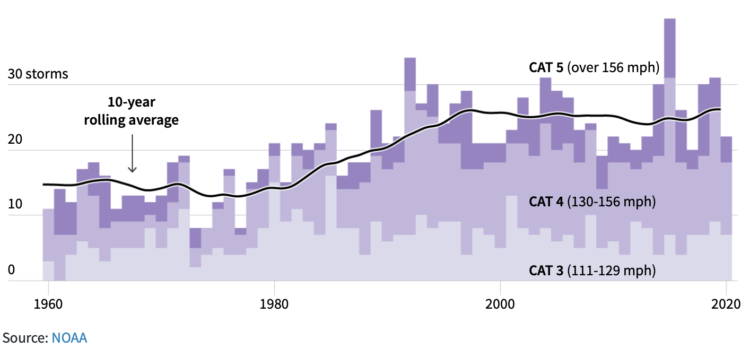
It used to be that climate changed seemed like something far off in the future, like something that would only affect future generations. But it’s looking more urgent these days. For Reuters, Chris Canipe, Matthew Green and Sam Hart show the “fingerprints of climate change” we saw this year.
-
Members Only

Here’s the good stuff for December in the last issue of the year.
-

It’s been a year. We saw a lot of charts. These are the best ones.
-
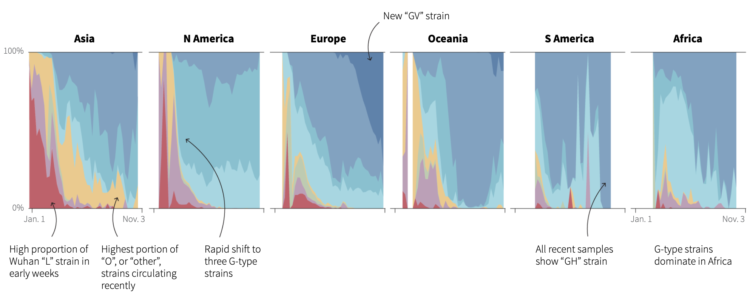
Reuters looked at how seven main strains of the virus evolved around the world:
The analysis shows there are currently seven main strains of the virus. The original strain, detected in the Chinese city of Wuhan in December 2019, is the L strain. The virus then mutated into the S strain at the beginning of 2020. That was followed by V and G strains. Strain G mutated yet further into strains GR, GH and GV. Several other infrequent mutations were collectively grouped together as strain O.
It’s interesting to see the continent multiples. Different approaches to the pandemic led to different rates of mutations and a different spread of strains.
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









