In case you’re on the market for a data sciencey type job, there were a number of them posted to the forums this past week, along with some other schtuff.
SEM infographics freelance — Working is picking up and I need help covering all my client requests for SEM infographics…
Designer needed for animated cartogram — I am a financial publisher in need of a designer to create a cartogram of world GDP growth by nation…
Data Visualization and Charting Business Manager — Bloomberg is looking for a passionate, experienced individual to join the Charts, Technical Analysis and Graphics Business…
Data Visualization Genius — Young, fast-growing digital media startup seeks data visualization or UI expert…
Interaction Designer — Do you believe, in a freshman-year kind of way, that design just might save the world?
P.S. I changed the “Finding a Job” forum to “Job Board” since that’s basically what it’s used for. Are you an employer looking for a qualified data person? Post it to the board. It’s free.
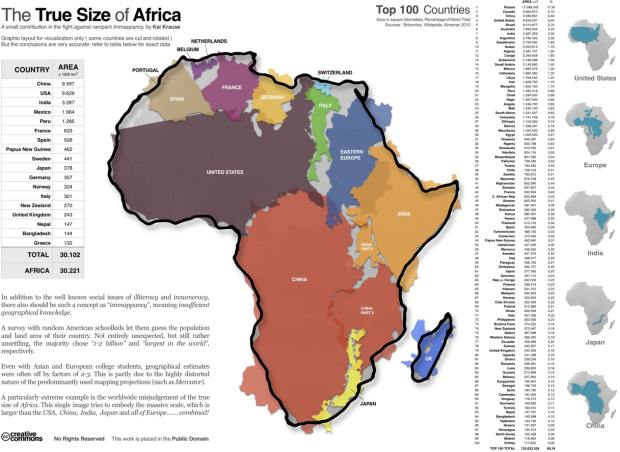

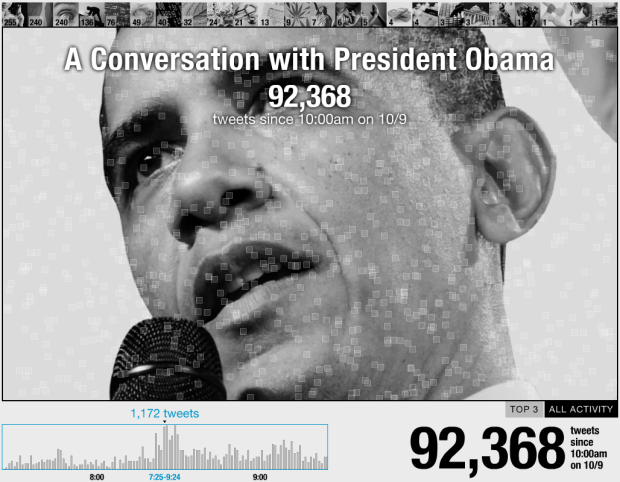
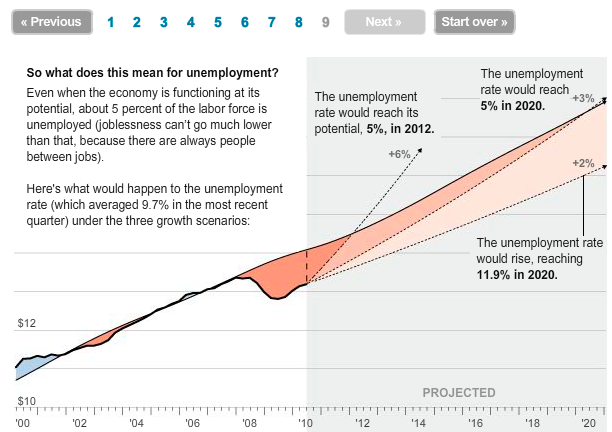
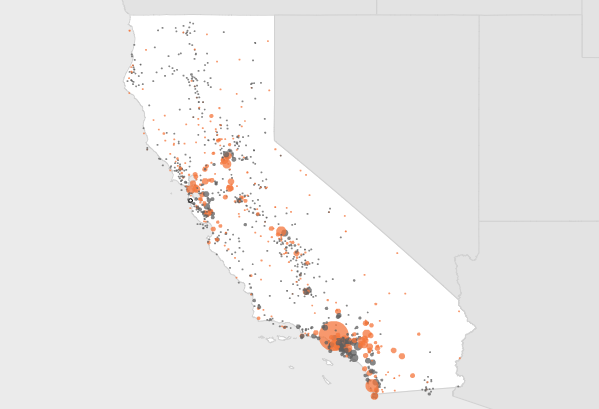
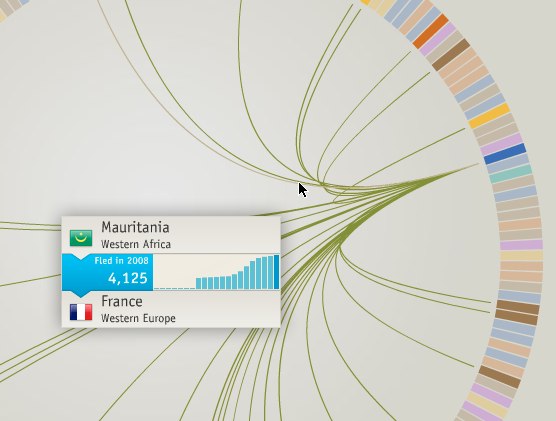
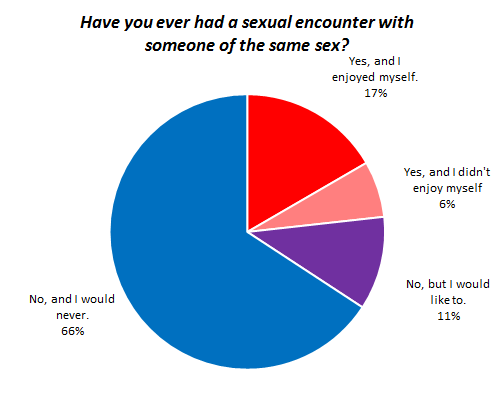
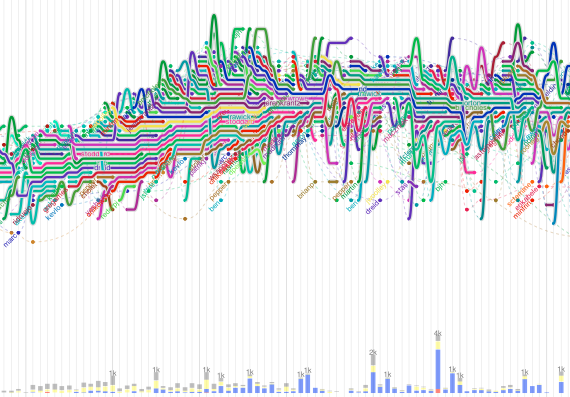
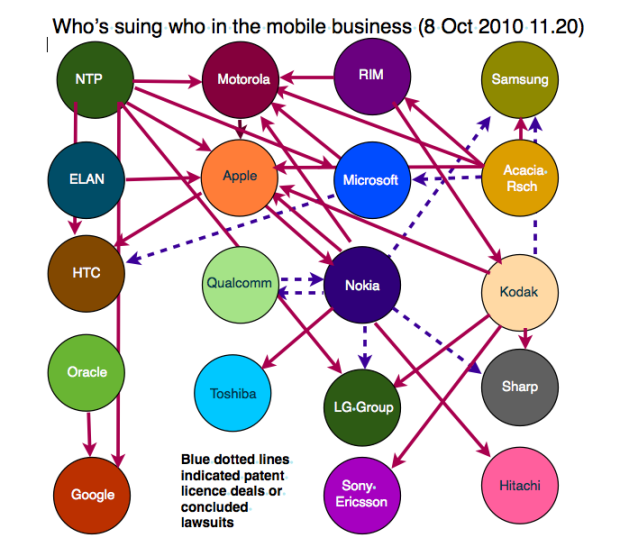

 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)










{kind=link}