 The best way to learn how to visualize data is to grab a dataset and see what you can do with it. You can read as many tips and tricks as you want, but you’re not going to get any better until you actually try. Contests are a fun way to do this.
The best way to learn how to visualize data is to grab a dataset and see what you can do with it. You can read as many tips and tricks as you want, but you’re not going to get any better until you actually try. Contests are a fun way to do this.
Participate
So here are a handful of visualization contests to get your hands dirty. Hey you might even win a couple of thousand dollars. Not that money matters to you, because as well all know, learning is your reward.
Hacking Education — A contest for developers and data crunchers. DonorsChoose.org has inspired $80 million in giving from 400,000 donors, helping 165,000 teachers at 43,000 schools, and the donation site has opened up this data. Can do you do something with it? Deadline: June 30, 2011.
Data In Sight — A hands-on competition in San Francisco’s SoMa district with surprise data sources. Some talks, lunch, dinner, and a 24-hour hackathon. Event date: June 24, 2011 (better to register your team early).
Tableau Interactive Viz Contest — This one is coming up the quickest, but is the most straightforward. Plus, you get a t-shirt just for entering. Grab some business, finance, or real estate data and go to town with Tableau Public. Deadline: June 3, 2011.
Know of any other data/visualization contests coming up? Let us know in the comments.
 The Pew Research churns out a lot of
The Pew Research churns out a lot of 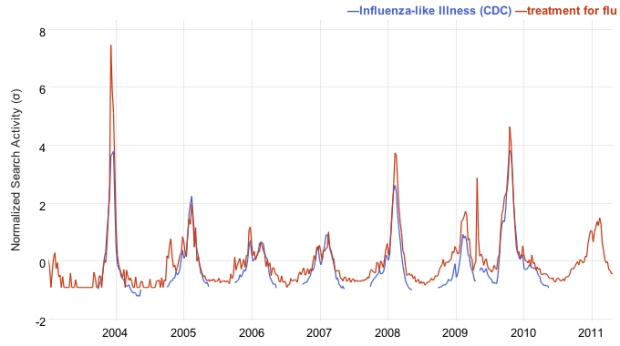
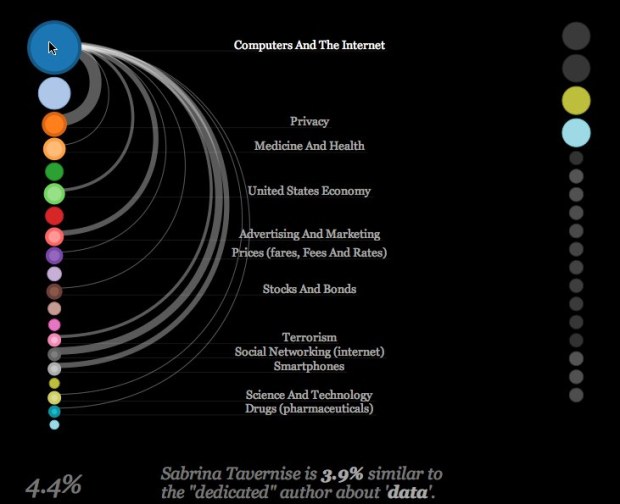
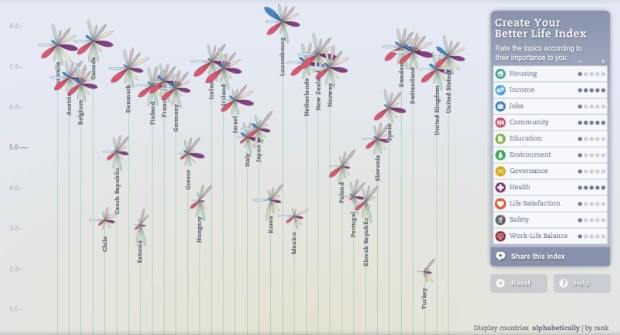
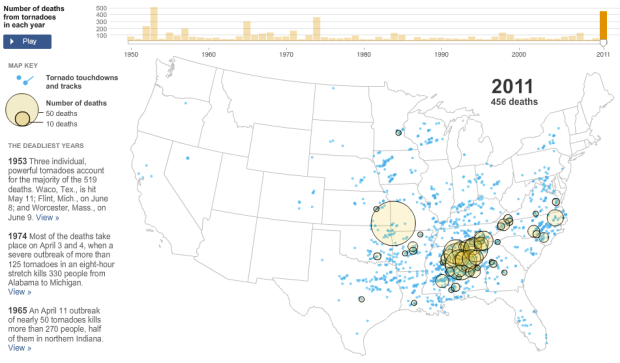
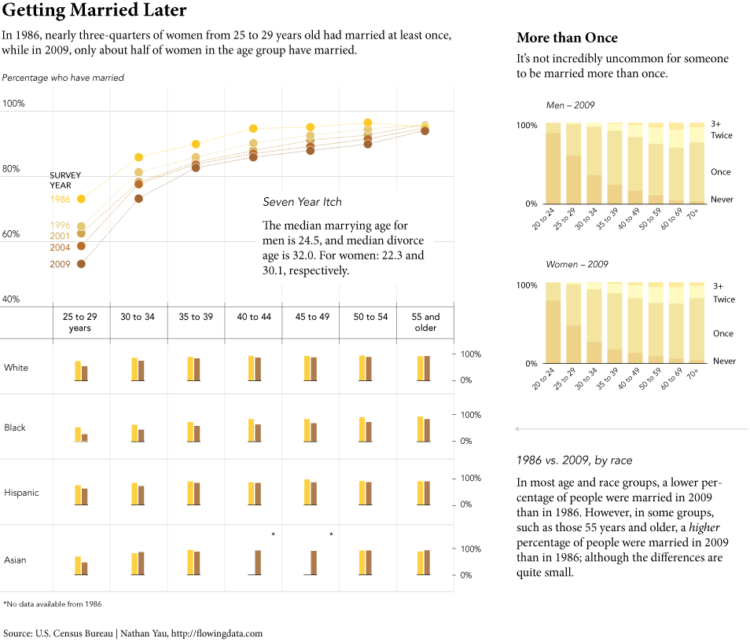
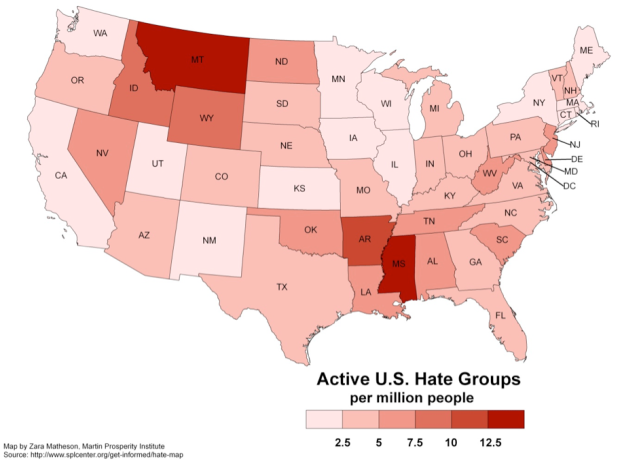


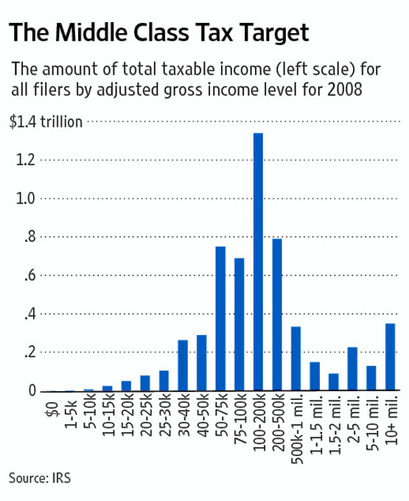





 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









