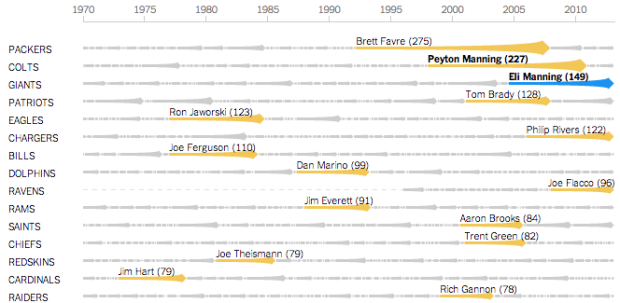
Mike Bostock, Shan Carter, and Kevin Quealy for The New York Times explore quarterback streaks in the National Football League since 1970. The longest streak for each team is highlighted yellow, and you can search for your favorite players either by mousing over streaks or via the dropdown/search menu.
Be sure to also check out the chart iterations of the interactive. First, a couple of bar graphs in R for a visual summary, and then 17 sketches later, out comes the finished product.
I’m surprised that many of the longest streaks took place in the 1970s and 1980s. You’d think with today’s rules, there’d be more in the latter half of the timespan. Then again, trades and quarterback rotations aren’t the same as they were back then either.








 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









