Michal Migurski thinks about finding the right job for the tool rather than the other way around:
Near the second half of most nerd debates, your likelihood of hearing the phrase “pick the right tool for the job” approaches 100% (cf. frameworks, rails, more rails, node, drupal, jquery, rails again). “Right tool for the job” is a conversation killer, because no shit. You shouldn’t be using the wrong tool. And yet, working in code is working in language (naming things is the second hard problem) so it’s equally in-bounds to debate the choice of job for the tool. “Right tool” assumes that the Job is a constant and the Tool is a variable, but this is an arbitrary choice and notably contradicted by our own research into the motivations of idealistic geeks.
Along the same lines, Frank Chimero on not trying any new tools for the year and how each represents someone’s perspective:
Everything that’s made has a bias, but simple implements—a hammer, a lever, a text editor—assume little and ask less. The tool doesn’t force the hand. But digital tools for information work are spookier. The tools can force the mind, since they have an ideological perspective baked into them. To best use the tool, you must think like the people who made it. This situation, at its best, is called learning. But more often than not, with my tools, it feels like the tail wagging the dog.
These approaches apply well to analysis and visualization. In the early goings especially, there tends to be an obsession with what tools to use. Which is best? Which is fastest? Which can handle the most data? Which makes everything beautiful? And yeah, it’s good to give these some thought in the beginning, but don’t get stuck asking so many questions or pondering so many scenarios that you never settle down and do actual work.
There’s always going to be a new application that promises to help you do something with your data. Work on this stuff long enough and you’ll find that you probably won’t need that new thing.
 Learning regular expressions tends to involve a lot of trial and error and can be confusing for newcomers.
Learning regular expressions tends to involve a lot of trial and error and can be confusing for newcomers. 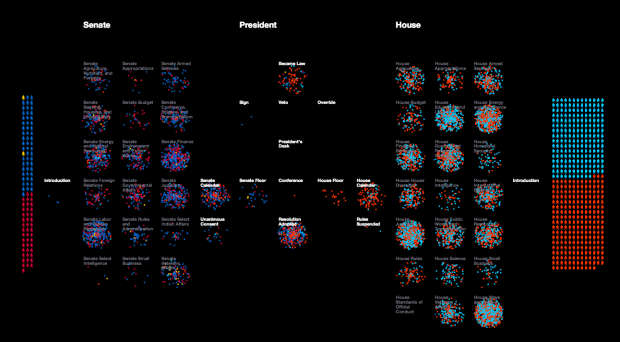
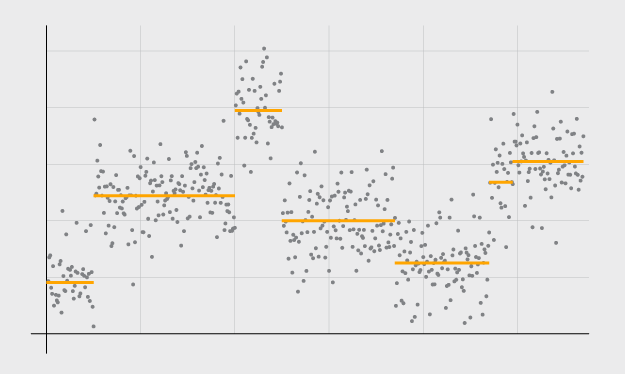
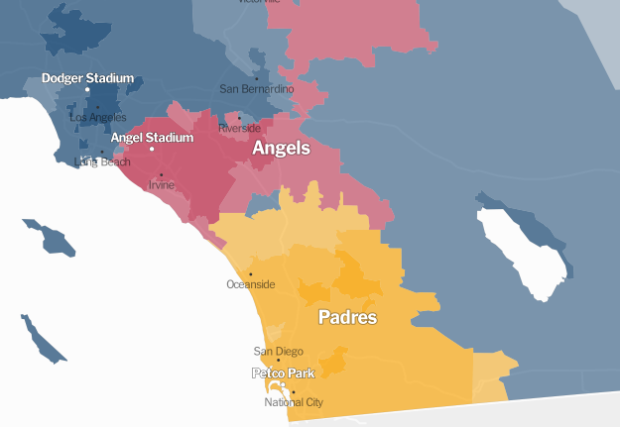

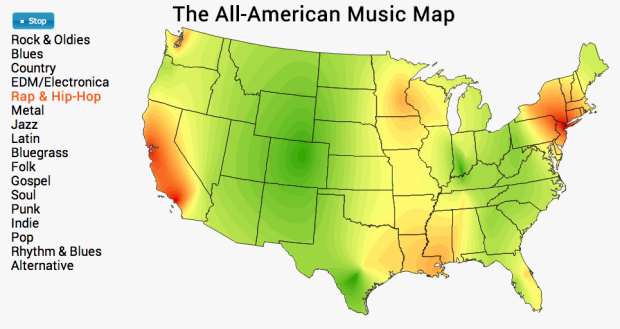
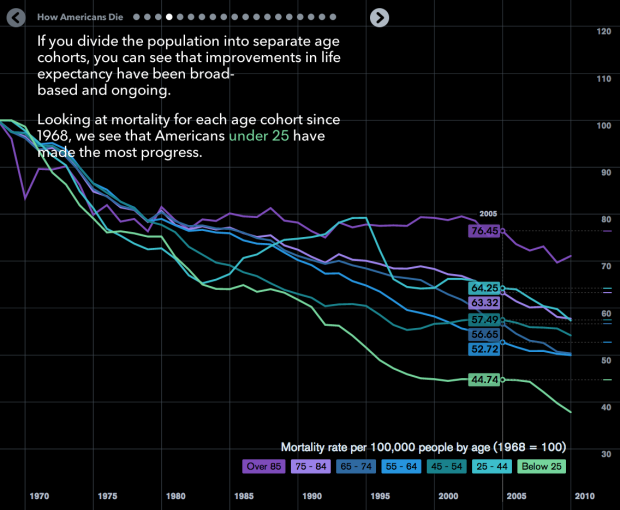

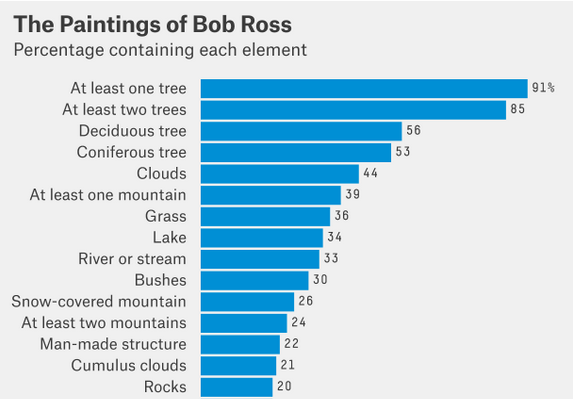
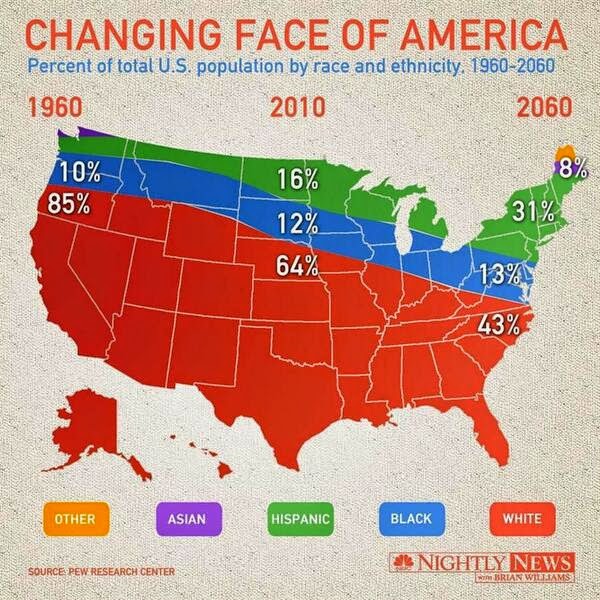
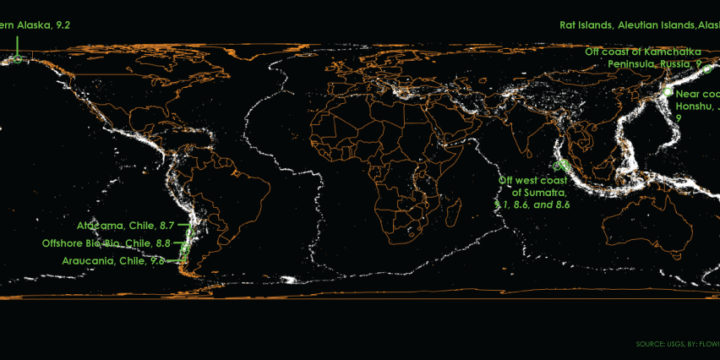
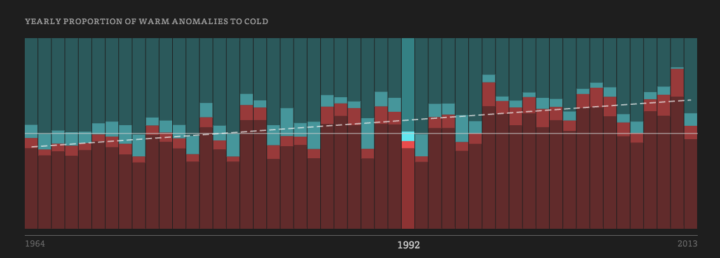
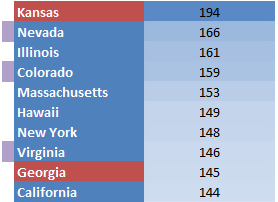 Pornhub continues their analysis of porn viewing demographics
Pornhub continues their analysis of porn viewing demographics 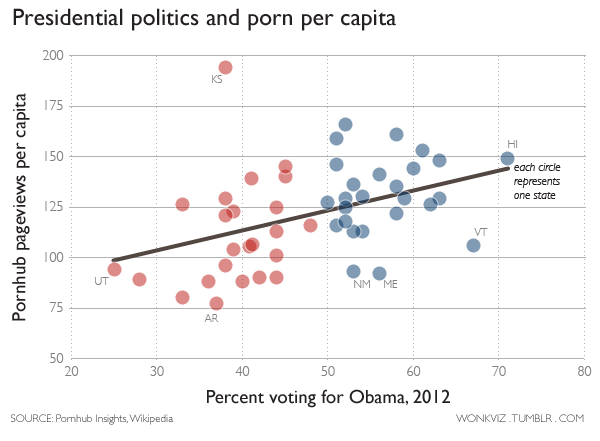
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









