The new R package miner is an interface to Minecraft via some simple R commands.
The miner package provides just a few simple functions to manipulate the game world: find or move a player’s position; add or remove blocks in the world; send a message to all players in the world. The functions are deliberately simple, designed to be used to build more complex tasks.
I’m thinking walkable data worlds in Minecraft.
I bought Minecraft for my three-year-old, but he didn’t understand the point when his LEGO bricks were within arm’s reach and there weren’t any funny noises or songs. Maybe the purchase wasn’t a total bust after all.
Here’s the full miner package guide.
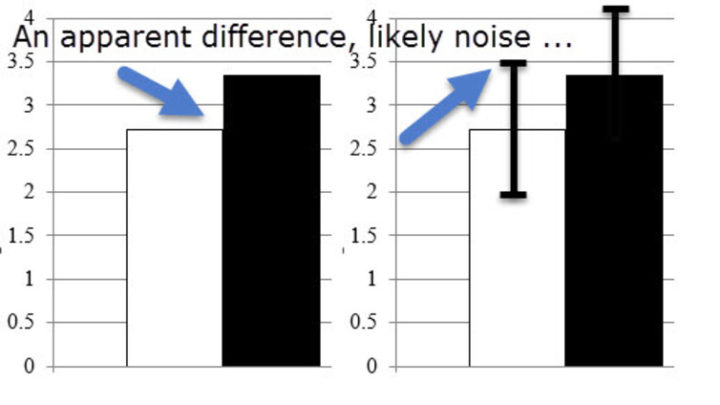
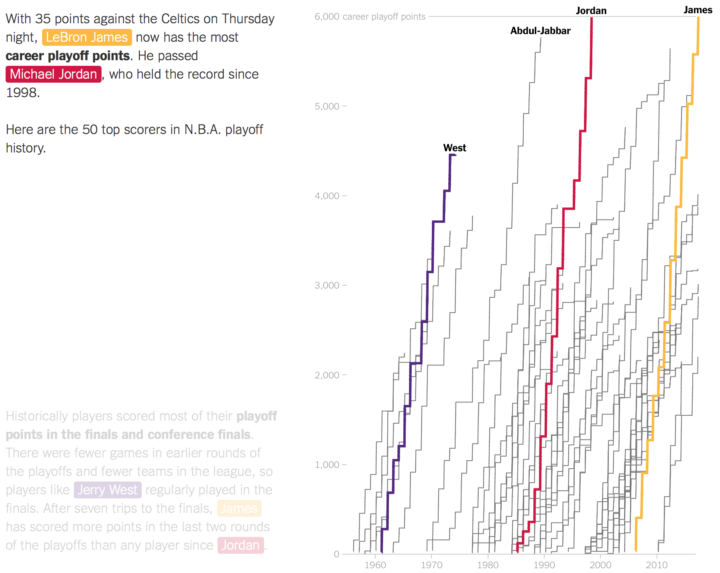

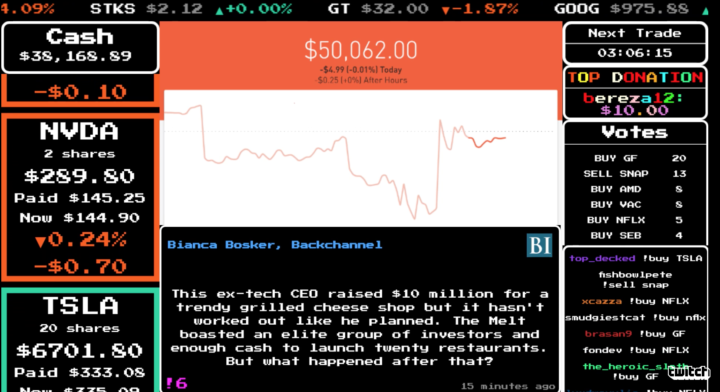
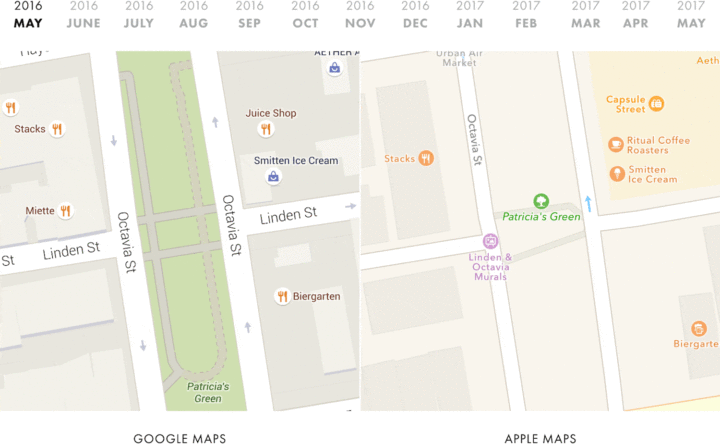
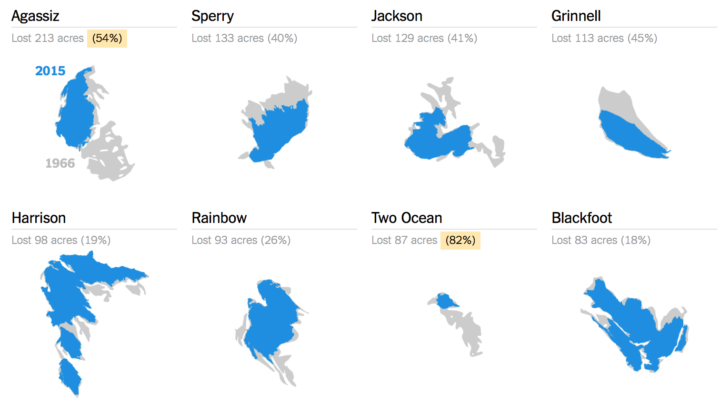
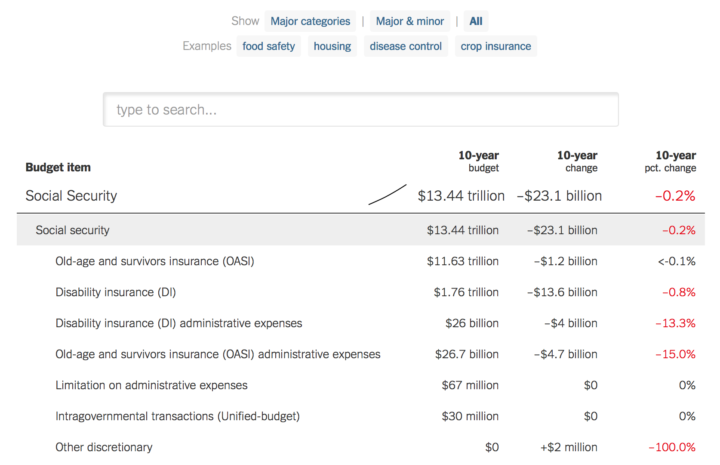
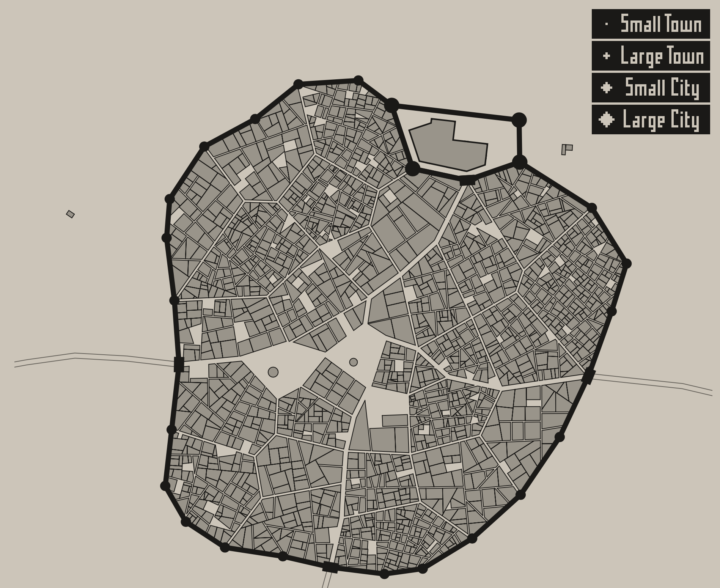
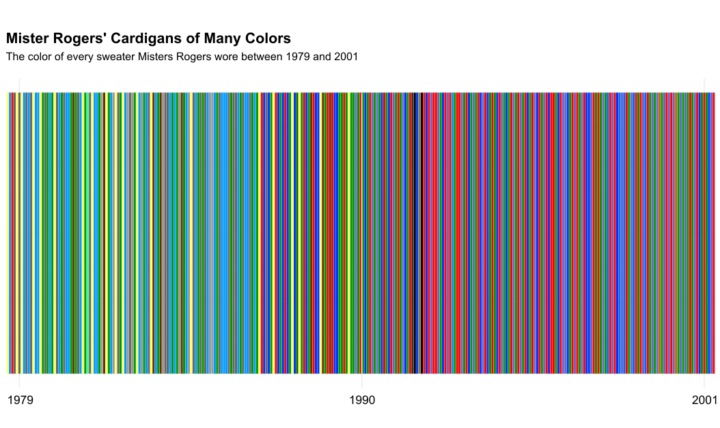


 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









