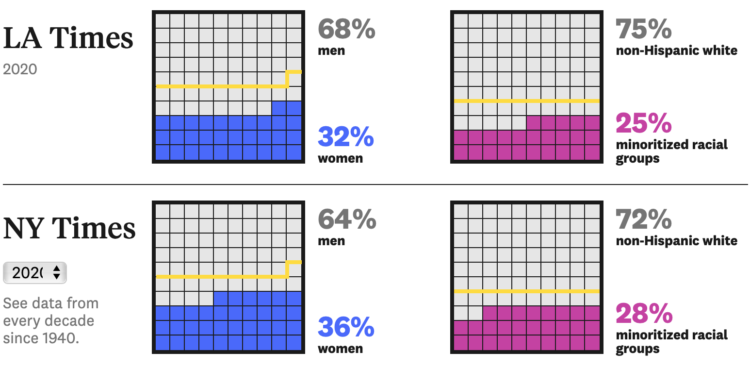
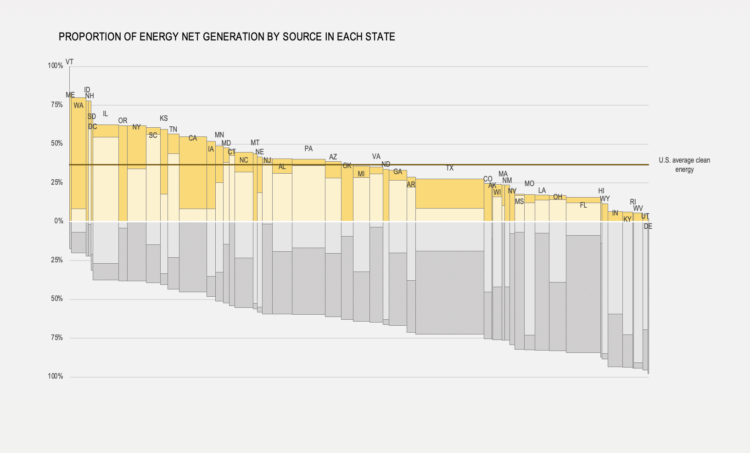
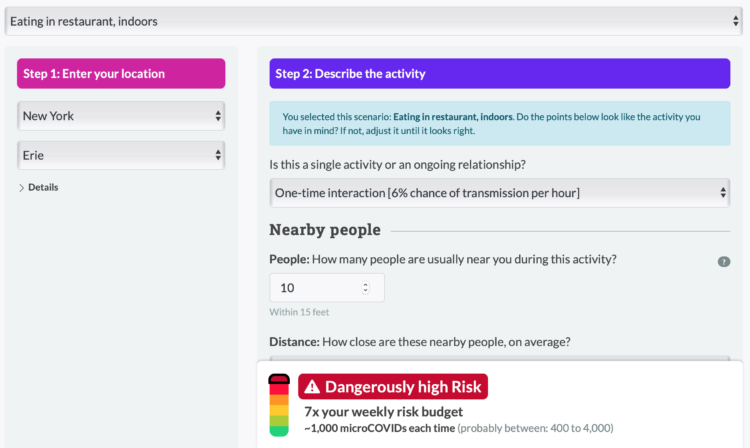
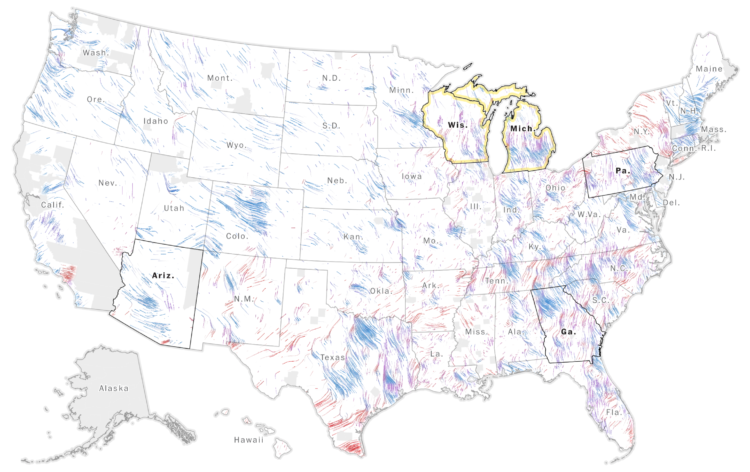
For The Pudding, Michelle McGhee analyzed representation in crossword puzzles. Some crossword publications do better than others.
As of December 2019, The USA Today puzzle is edited by Erik Agard, a 27-year old crossword champ who told me, “bringing some balance on the representation front is something I actively try to do.” A prominent crossword blogger called USA Today’s puzzle “the most interesting, innovative, and provocative daily crossword” out right now. Let’s take a look at how USA Today, and other publications, are taking a puzzle that’s been called too old, too white, too male, and changing it up.
The story also comes with playable, data-generated puzzles so that you can feel the difference over decades.






 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









