Jenka Gurfinkel discusses the appearance of the American smile in AI-generated images and…
Statistics
More than mean, median, and mode.
-

AI and the American smile
-
NYT switches to CDC data for their Covid dashboard
After three years, The New York Times is switching away from local data…
-
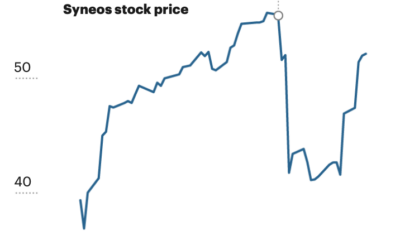
Curiously timed stock trades by ultra-wealthy
Continuing an analysis of IRS records, Robert Faturechi and Ellis Simani for ProPublica…
-
NBA will track players with a third dimension
The NBA currently uses player-tracking that estimates player position on the court in…
-

Data warehouse at the supermarket
Grocery stores with loyalty programs collect data on what and when you buy…
-

Guide for working with machine learning datasets
As part of the Knowing Machines research project, A Critical Field Guide for…
-
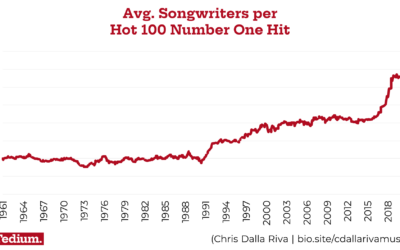
Why modern popular songs have so many more writing credits
For Tedium, Chris Dalla Riva examined why the number of credited songwriters per…
-
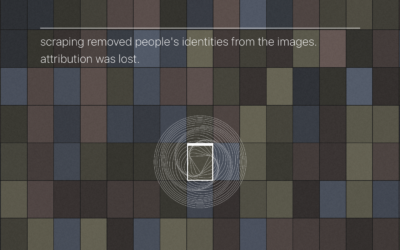
Sources and attribution for AI-generated images
AI-based image generation take bits and pieces from existing people-made images and tries…
-
Generating music from text
Researchers at Google built a model that generates music based on brief text…
-
Manual removal of harmful text to train AI models
AI training data comes from the internet, and as we know but maybe…
-

Bias in AI-generated images
Lensa is an app that lets you retouch photos, and it recently added…
-

Generative AI trade-offs
People have been having fun with generative AI lately. Enter a prompt and…
-
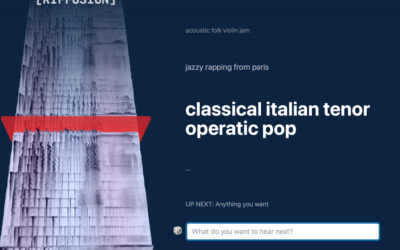
Stable Diffusion to generate spectrograms to convert to sounds
Stable Diffusion is an AI model that lets you enter text to generate…
-

Digital face aging with neural network
Disney Research demonstrates their use of neural networks to seamlessly age and de-age…
-

Building a happy life, interpreted through data
How to Build a Happy Life from The Atlantic is a podcast on…
-
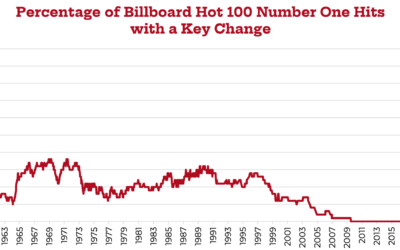
Decline of key changes in popular music
Chris Dalla Riva analyzed key changes in songs that made the Billboard Hot…
-

Sleuthing for birth dates, with just TikTok profiles as clue
TikTok user notkahnjunior figures out people’s birth dates through the psuedo-privacy of the…
-
AI-based image generation ethics
AI-based image generation is having a moment. Time some text and you can…
-

Educational statistics illustrations
Allison Horst often illustrates data science concepts and tools with anthropomorphized shapes and…
-
Algorithmic rent increase
It’s growing more common for landlords to use software to set the rental…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









