Emma Pierson and Kowe Kadoma, for Fred Hutchinson Cancer Center, have a short…
Statistics
More than mean, median, and mode.
-

Building fair algorithms
-
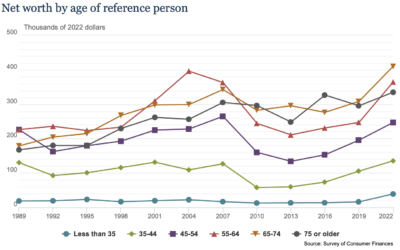
Data on net worth, income, and savings
Data for the 2022 Survey of Consumer Finances, from the Federal Reserve Board,…
-
When Mike Breen announces “Bang!”
Mike Breen is a well-known NBA basketball announcer. When a player hits a…
-
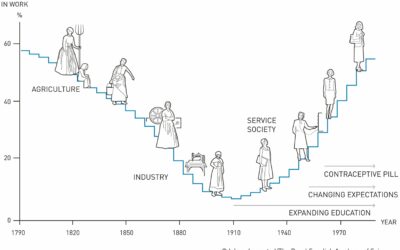
Nobel Prize for research in global labor markets, using historical data
Claudia Goldin, an economist at Harvard, has won the Nobel Prize in Economics.…
-
News organizations blocking OpenAI
Ben Welsh has a running list of the news organizations blocking OpenAI crawlers:…
-
Crows might understand probabilities
Researchers at the University of Tübingen are studying crows’ abilities to understand statistical…
-
Tattoos and impulsiveness dataset
For their research on tattoos and choice, Bradley Ruffle and Anne Wilson provide…
-
Flawed Rotten Tomatoes ratings
Rotten Tomatoes aggregates movie reviews to spit out a freshness score for each…
-
Supermarket provides AI-driven meal planner and is disappointed by the internet using it to output weird recipes
A supermarket chain in New Zealand offered an AI-based recipe generator, and of…
-
Finding a troll’s identity
A troll kept leaving comments on a woman’s TikTok videos, so she figured…
-
Save recipes to your email
Yums, by Matthew Phillips, is a quick and simple way to save recipes…
-
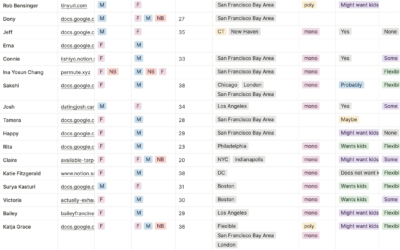
Directory of date-me docs
Instead of using dating apps, some have turned to the date-me doc, which…
-
Honesty research likely faked data
Research by Dan Ariely and Francesca Gino suggested that people were more honest…
-
Manual data labeling behind the AI
One of the things that makes AI seem neat is that it sometimes…
-

Outsourced work and generative AI
For Rest of World, Andrew Deck turned the AI focus on outsourced workers,…
-

Introduction to statistical learning, with Python examples
An Introduction to Statistical Learning, with Applications in R by Gareth James, Daniela…
-

Oddly specific ad profiles
Advertising funds a big chunk of the web, but for advertisers to continue…
-

Astericking NBA champions
It seems to have grown more common for basketball fans to complain that…
-
Changes to Blackjack payouts so that gamblers lose more to casinos
Katherine Sayre, for The Wall Street Journal, on Las Vegas casinos squeezing out…
-

Demonstrating how large language models work
You might’ve heard about large language models lately. They’re the “brains” behind recent…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









