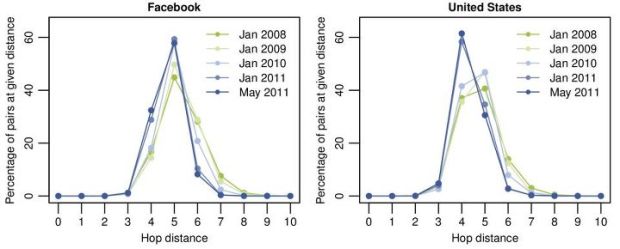
Testing the idea of six degrees of separation, first proposed by Frigyes Karinthy, the Facebook Data Team and researchers at the Università degli Studi di Milano found that most of us are connected by even fewer degrees, and average separation is getting smaller:
While we will never know if it was true in 1929, the scale and international reach of Facebook allows us to finally perform this study on a global scale. Using state-of-the-art algorithms developed at the Laboratory for Web Algorithmics of the Università degli Studi di Milano, we were able to approximate the number of hops between all pairs of individuals on Facebook. We found that six degrees actually overstates the number of links between typical pairs of users: While 99.6% of all pairs of users are connected by paths with 5 degrees (6 hops), 92% are connected by only four degrees (5 hops). And as Facebook has grown over the years, representing an ever larger fraction of the global population, it has become steadily more connected. The average distance in 2008 was 5.28 hops, while now it is 4.74.
So when you see random strangers, shake their hands and say hello. You’re practically best friends.
Too bad there isn’t an interactive we can enter random names on to see how close we are.
[Facebook]





 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









