There’s a subreddit where people share a story and ask if they’re the…
Statistics
More than mean, median, and mode.
-
AI says if you’re the a**hole
-
Facebook doesn’t seem to fully know how their data is used internally
Lorenzo Franceschi reporting for Motherboard on a leaked Facebook document:
“We do not… -
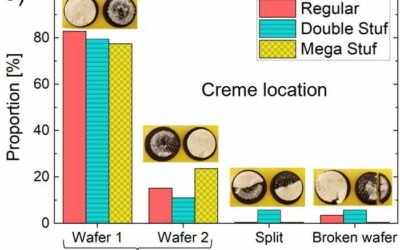
Fracture and flow of Oreo cookies
Crystal Owens, Max Fan, John Hart, and Gareth McKinley from Massachusetts Institute of…
-
Tracking the CIA to demo phone tracking
Sam Biddle and Jack Poulson for The Intercept reporting on Anomaly Six, a…
-
Applying sentiment analysis usefully
Sentiment analysis can be fun to apply to varying types of text, but…
-
Calculating win probabilities
Zack Capozzi, for USA Lacrosse Magazine, explains how he calculates win probabilities pre-game…
-
Scraping public data ruled legal
For TechCrunch, Zack Whittaker reporting:
In its second ruling on Monday, the Ninth… -
Tax services want your data
Taxes are due today in the U.S. (yay). Geoffrey A. Fowler for The…
-
Lessons learned from making covid dashboards
For Nature, Lynne Peeples spoke to the people behind many of the popular…
-

1950 Census released by U.S. National Archives
For privacy reasons, there’s a 72-year restriction on individual Census records, which include…
-
Increasing mortality baseline
There was a time not that long ago when a hundred covid deaths…
-
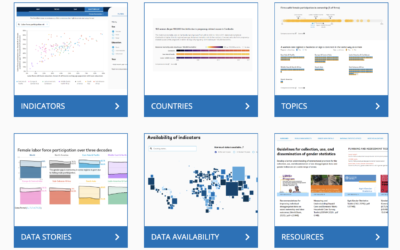
World Bank’s Gender Data Portal
In an effort to make gender inequalities more obvious, World Bank updated their…
-
Inflation explained with eggs
The prices of everything seem to be rising a lot lately. Why? For…
-

Recontextualized media
The Media Manipulation Casebook summarizes how bad-intentioned people take media from past events,…
-
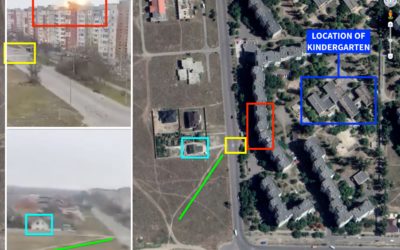
Visual forensics to spot fake videos and photos
It’s easy for anyone to grab a picture or video and claim that…
-

Statistician answers stat questions
[arve url=”https://www.youtube.com/watch?v=QW3KRaz4aI4″ /]
For Wired, stat professor Jeffrey Rosenthal answered statistics questions from… -
Crisis Text Line and data sharing
Crisis Text Line was sharing data with a for-profit business started by its…
-
Spotting spurious correlations in health news
When it comes to diet and health, you might see one day that…
-

Optimized Wordle solver
In case you’re not so good with the words, but feel the social…
-

Joke machine learning projects to advance your career
In an automated job climate that analyzes resumes and inspects social profiles, it…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →








