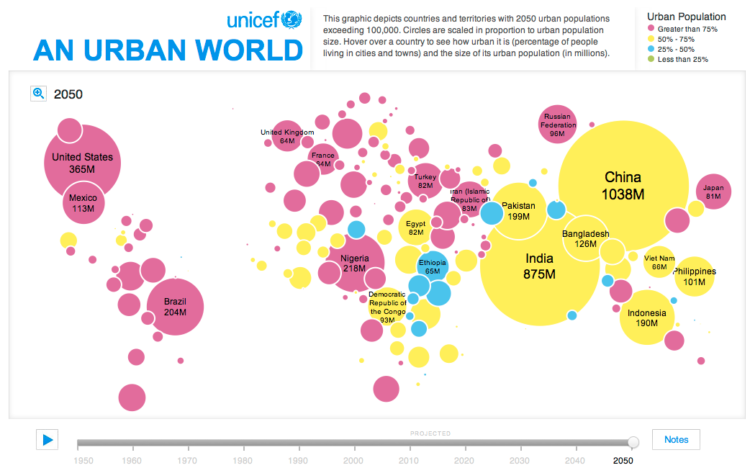
In this simple interactive animation by Periscopic, in partnership with UNICEF, we see the changes in urban population from 1950 up to present, through projections for 2050. Circle size represents urban population and color is an indicator for the percentage of people living in cities or towns.
The color choice for the continuous scale is not ideal, but I think they were working within the bounds of the existing print report.
For the map project, we were working with pre-existing content. They had produced the map for their print report, so we had to make it look as similar as possible to that. I know they didn’t use a Dorling cartogram, but I think their intention was to be similar to one. Certain sacrifices were made in order for it to fit the 2-page spread in the report. Unfortunately, the online version had to keep the same locations.
[UNICEF | Thanks, Dino]


 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)










{kind=link}