A big thank you to the FlowingData sponsors. Without them, I would not be able to do what I do, and this site wouldn’t exist. Check ’em out. They help you do stuff with data.
IDV Solutions Visual Fusion — Business intelligence software for building focused apps that unite data from virtually any data source in a visual, interactive context for better insight and understanding.
Tableau Software — Tableau Software helps people see and understand data. Ranked by Gartner in 2011 as the world’s fastest growing business intelligence company, Tableau helps anyone quickly and easily analyze, visualize and share information.
Column Five Media — Whether you are a startup that is just beginning to get the word out about your product, or a Fortune 500 company looking to be more social, they can help you create exciting visual content – and then ensure that people actually see it.
InstantAtlas — Enables information analysts and researchers to create highly-interactive online reporting solutions that combine statistics and map data to improve data visualization, enhance communication, and engage people in more informed decision making.
Want to sponsor FlowingData? Send interest to [email protected] for more details.
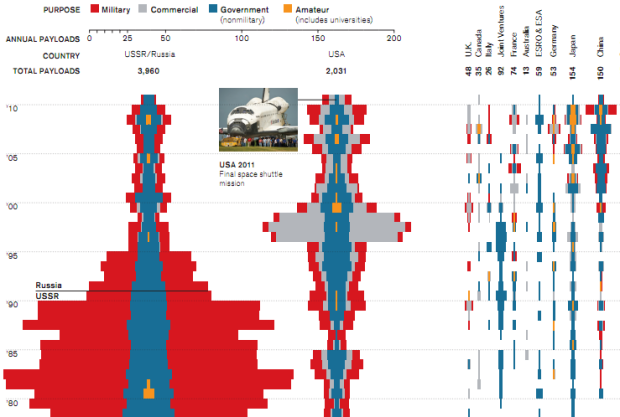


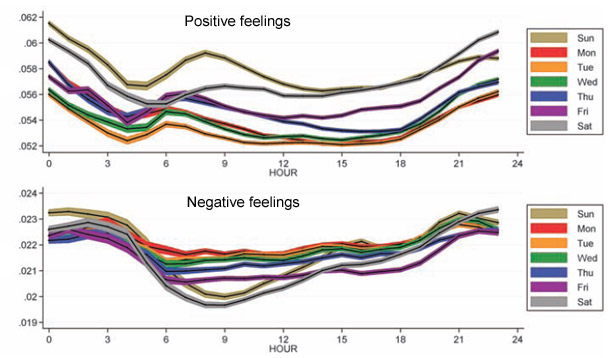
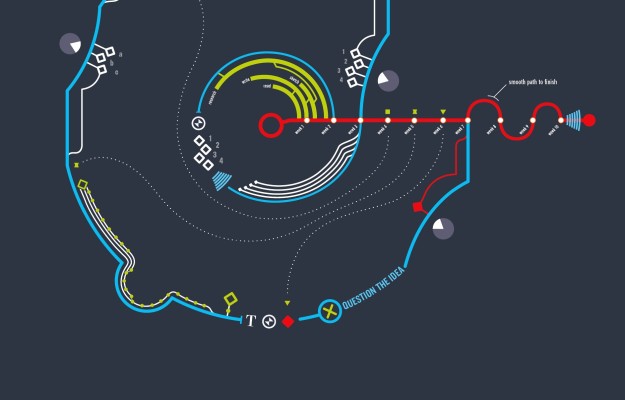
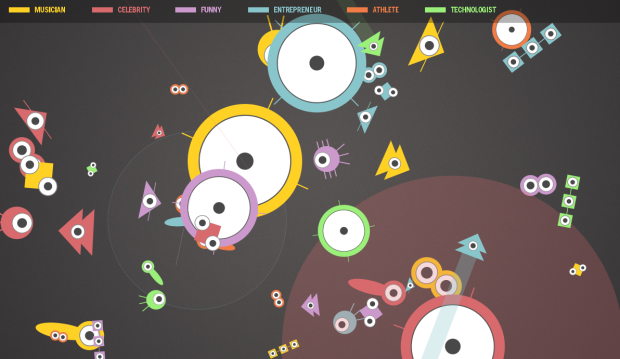



 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









