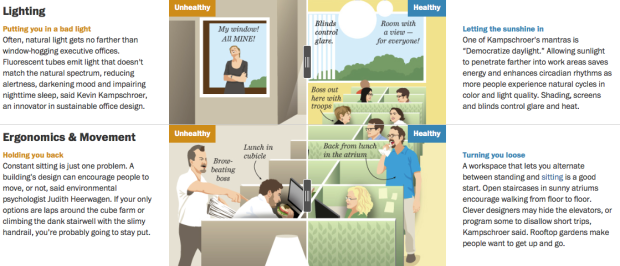
In an interesting use of the before-and-after slider, this Washington Post graphic by Bonnie Berkowitz and Laura Stanton contrasts an unhealthy office environment against a healthy one.
As a whole, the graphic represents a full office, and the section is broken into categories for an unhealthy environment on the left and a healthy one on the right. For each section, slide all the way to the left or right to see a fuller picture of the respective habit, covering topics such as ergonomics, hygiene, and air quality.
FYI: Rats and dead plants send the wrong message to your employees.







 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









