This past month an old chart type poked its head out from behind the trees and I’m here for it.
This past month an old chart type poked its head out from behind the trees and I’m here for it.
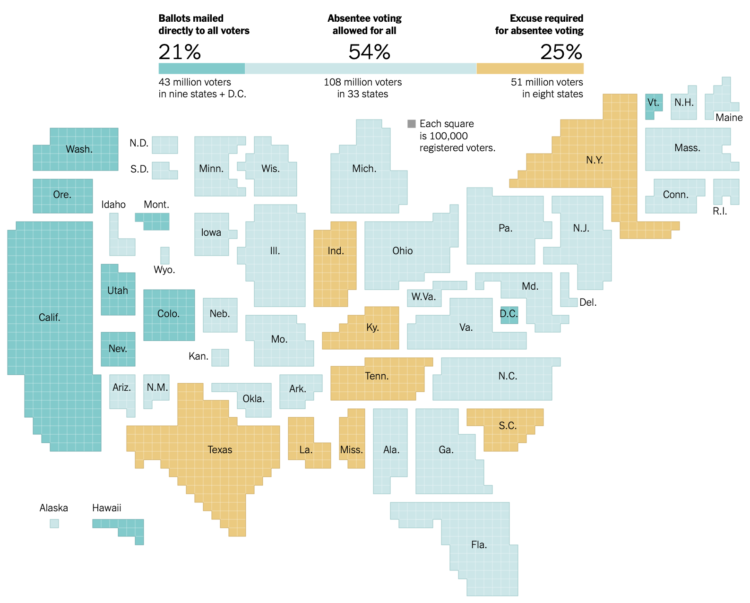
There’s going to be a lot more voting by mail this year. The New York Times shows what each state is doing. It’s a cartogram. So it must be election season.
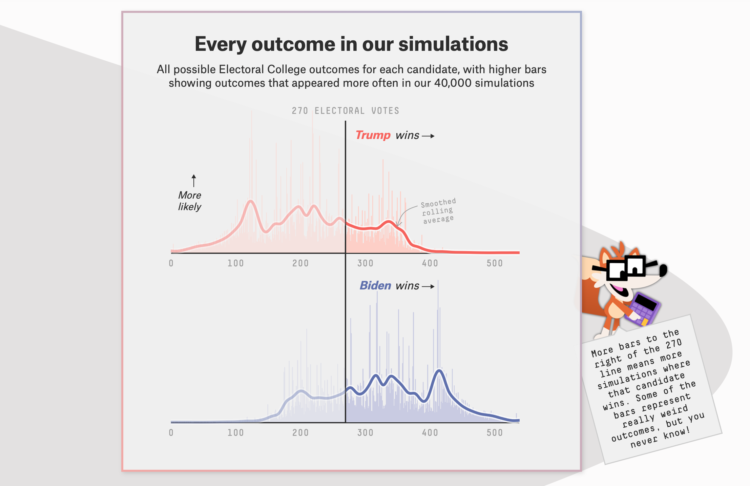
The election is coming. FiveThirtyEight just launched their forecast with a look at the numbers from several angles. Maps, histograms, beeswarms, and line charts, oh my. There is also a character named Fivey Fox, which is like Microsoft’s old Clippy providing hints and tips to interpret the results.
One thing you’ll notice, and I think newsrooms have been working towards this, there’s a lot of uncertainty built into the views. It’s clear there are multiple hypothetical outcomes and there’s minimal use of percentages, opting for fuzzier sounding odds.
Remember when election forecasting went the opposite direction? They tried to build more concrete conclusions than talking heads. Now pundits frequently talk about the numbers (maybe misinterpreted at times), and the forecasts focus on all possible outcomes instead of what’s most likely to happen.

Slime mold are single-celled organisms that can work together to form multicellular structures. Antonio Sánchez Chinchón used slime mold simulations generate these images:
This post talks about a generative system called Physarum model, which simulates the evolution of a colony of extremely simple organisms that, under certain environmental conditions, result into complex behaviors. Apart from the scientific interest of the topic, this model produce impressive images like this one, that I call The Death of a Red Dwarf
You can check out the code, a combination of R and C++, on GitHub.
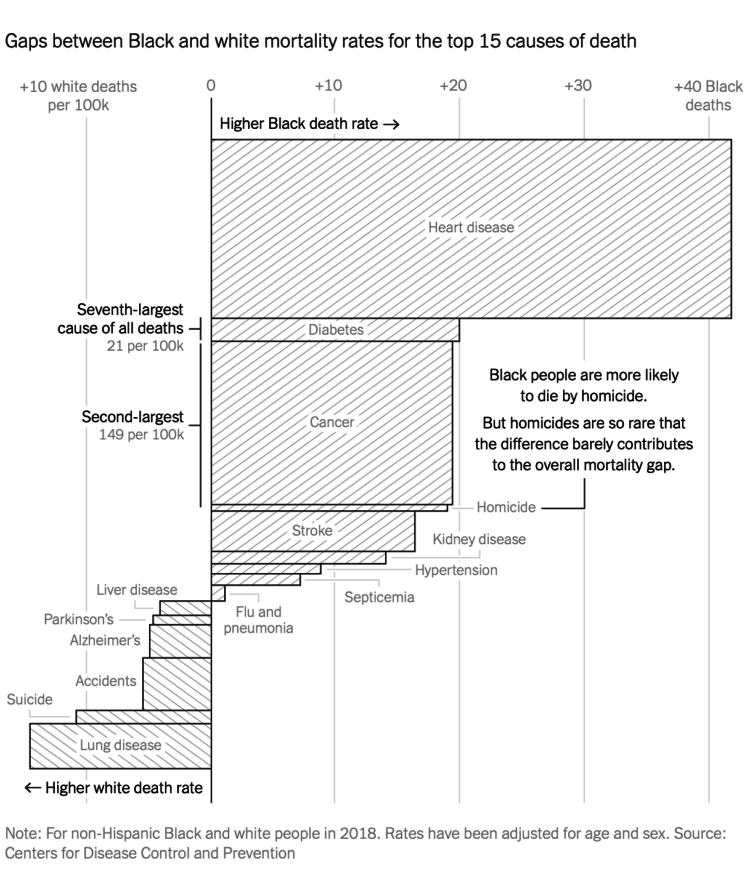
For NYT Opinion, Gus Wezerek charted the gaps between white and black mortality rate:
If Black people had died at the same age-adjusted rate as white people in 2018, they would have avoided 65,000 premature, excess deaths — the equivalent of three coach buses filled with Black people crashing and killing them all every day of the year.
…oof.
The variable width bar chart above is one of several graphics in the piece. Height represents rate. Width represents the gap. Direction represents which group has the higher rate.

Liana Finck for Man Repeller draws out the new timeline. I’m a couple of decades removed from this timeline, but it doesn’t look very fun. I’m always down to plant some scallions though. [via swissmiss]
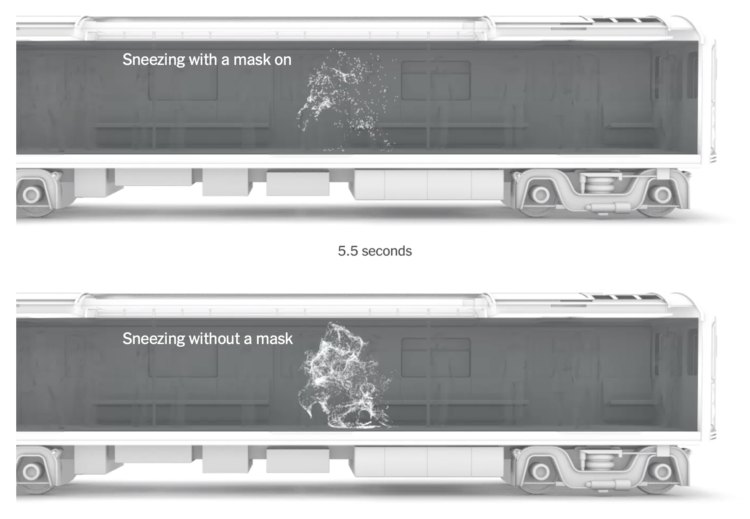
If someone sneezes in a closed space, you hope that the area has good ventilation, because those sneeze particles are going to spread. The New York Times explains in the context of a subway train.
Wear a mask.
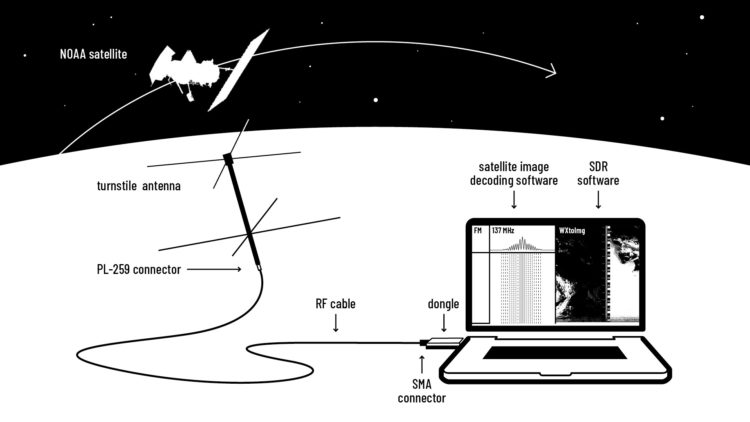
You can basically hook up an antennae to your laptop and start receiving images from space. This DIY guide from Public Lab amazes me.
The NOAA satellites have inbuilt radio antennas that transmit the data collected by the AVHRR instrument on a frequency in the 137 MHz range. To minimise interference between satellites, each NOAA satellite transmits on a different frequency within the 137 MHz range.
[…]
Your antenna is a sensor. It catches electromagnetic waves and transforms them into an electrical current i.e. an electrical signal. All antennas are tuned to specific frequency ranges meaning that they receive or transmit these frequencies best. Most antennas are directional.
I need to try this.
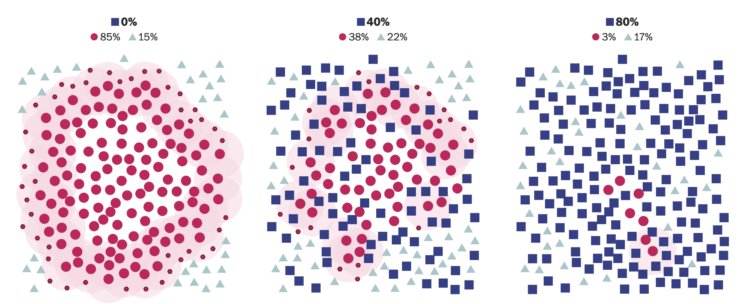
Herd immunity works when you have enough people who are immune to a disease, maybe because they already got it or there’s a vaccine, so that the disease can’t spread anymore to those who don’t have a resistance. For The Washington Post, Harry Stevens is back with simulitis to demonstrate how this works in greater detail.
It starts at the individual level, generalizes to a larger group, and then zooms out to the more concrete state level. It ends with an interactive that lets you test the thresholds yourself.
Each step builds on the previous, which provides clarity to an otherwise abstract idea.

We know the big ones. Now here are the small ones. Focused. Efficient.
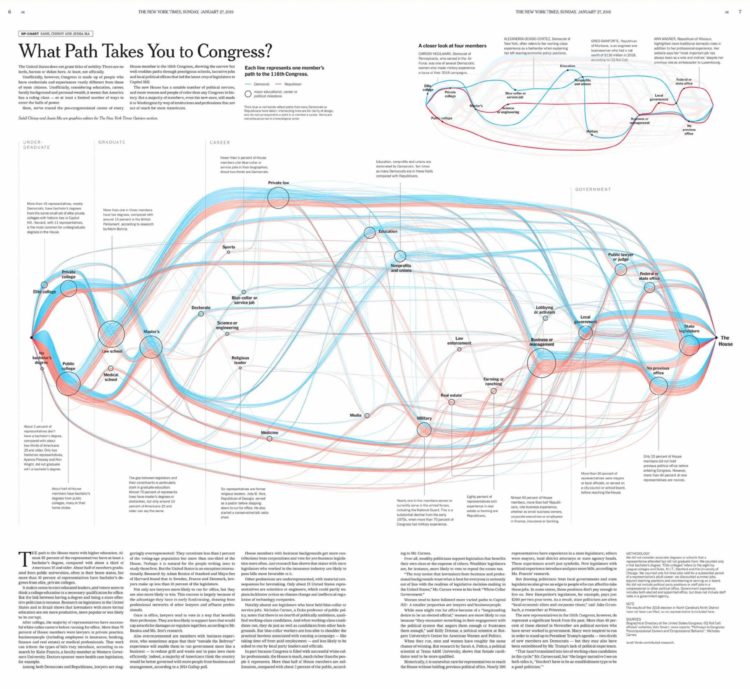
Malofiej, which in the visual journalism sphere is a high-tier honor to win each year, announced the winners for 2019. Congratulations to Sahil Chinoy and Jessia Ma for The New York Times on their Best of Show in print. They showed the various paths to Congress. And congrats to National Geographic for Best of Show in digital. They showed the moons.
Check out all of the medal winners here. Lots of good stuff.
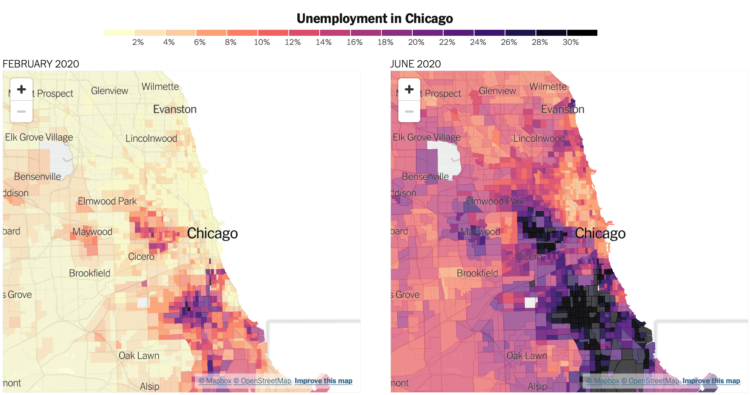
We’ve been hearing a lot about national unemployment rate, but it’s not uniformly distributed across the country. Some areas are a lot higher, some places are a lot lower, and there are places in between. To see the variation across the United States, Yair Ghitza and Mark Steitz estimated unemployment at the tract level.
Quoctrung Bui and Emily Badger for NYT’s The Upshot have the maps and histograms zooming in on places where unemployment is the highest.

With Joe Biden calling for 100% clean electricity, John Muyskens and Juliet Eilperin for The Washington Post looked at where states are at now in terms of electricity generation.
The variable width bar chart above uses a column for each state. Clean electricity stacks on the top and fossil fuels stack on the bottom, each representing a percentage of total generation. Column width represents total electricity for each state.
It reminds me of the spending graphic by Interactive Things in 2010. I think variable width is about to be a thing again.
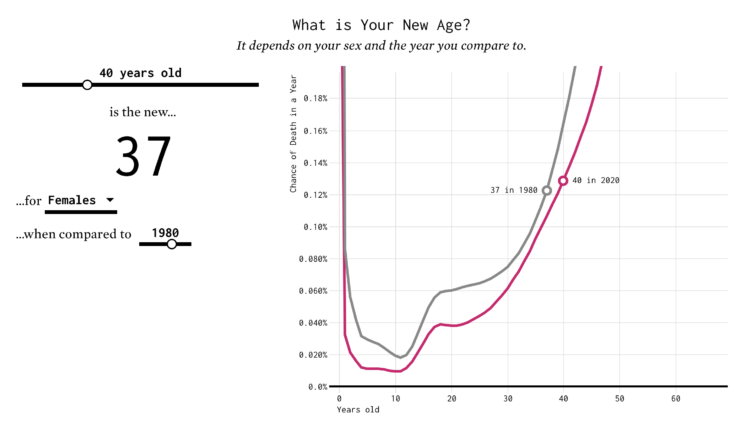
You’ve probably heard the lines about how “40 is the new 30” or “30 is the new 20.” What is this based on? I tried to solve the problem using life expectancy data. Your age is the new age.

Between 1802 and 1817, James Sowerby cataloged and illustrated 718 minerals across seven volumes. Nicholas Rougeux restored all of the illustrations over several months, carefully arranged them by color, and made them browsable on a page. The result: British & Exotic Mineralogy.
Read about the slow process here. Also in poster form.

Here’s the good stuff for July.
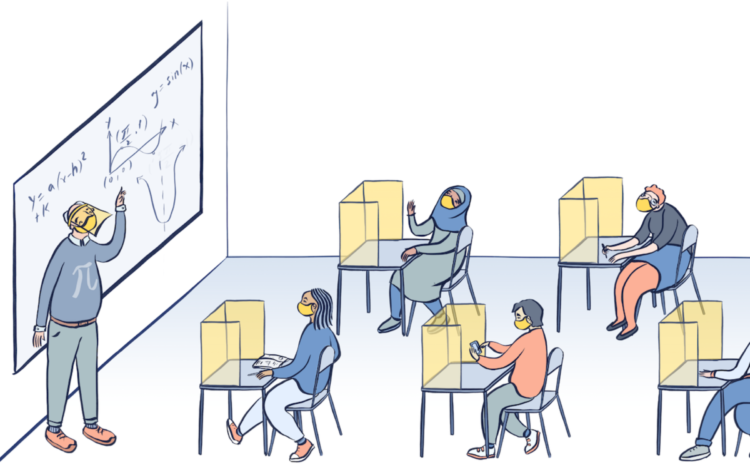
Dana Goldstein, with illustrations by Yuliya Parshina-Kottas, imagines what school might look like if students go back. Face shields, distancing, masks, and pods.
I’m having trouble imagining any of this working in practice, especially with the young ones.

Watch enough YouTube, and you end up in a bubble of videos catered to everything you like and believe in. TheirTube, by Tomo Kihara and Polina Alexeenko and funded by the Mozilla Foundation, imagines the point of view of six personas:
Each of these TheirTube personas is informed by interviews with real YouTube users who experienced similar recommendation bubbles. Six YouTube accounts were created in order to simulate the interviewees’ experiences. These accounts subscribe to the channels that the interviewees followed, and watches videos from these channels to reproduce a similar viewing history and a recommendation bubble. Everyday, TheirTube retrieves the recommendations that shows up on their Youtube home page.
In case you’re wondering what my YouTube homepage looks like — and I know you are — just watch every J. Kenji López-Alt upload, and you’ll be just about there.
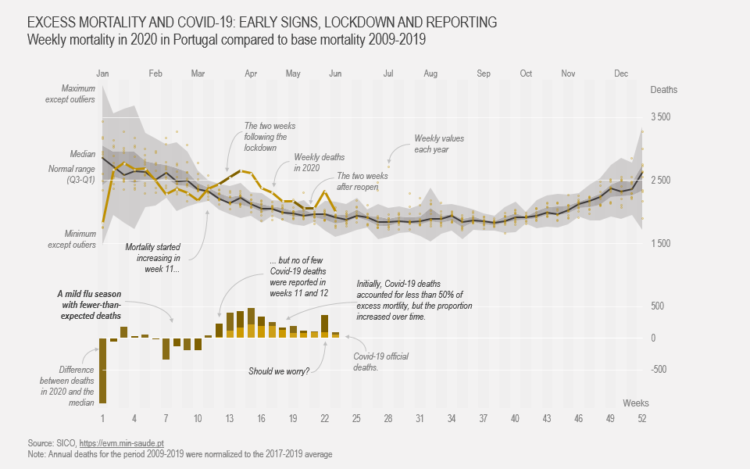
Show current evolution against expected historical variability and add one or more series that could account for the difference.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.










