George Mauer highlights how a hacker might access other people’s data by putting an equal sign in a CSV file, so that an import to Microsoft or Google Sheets runs a value as a formula, even if it’s quoted as a string.
The attacker starts the cell with their trusty = symbol prefix and then points IMPORTXML to a server they control, appending as a querystring of spreadsheet data. Now they can open up their server log and bam! Data that isn’t theirs. Try it yourself with a Requestb.in.
The ultra sinister thing here? No warnings, no popups, no reason to think that anything is amiss. The attacker just enters a similarly formatted time/issue/whatever entry, eventually an administrator attempts to view a CSV export and all that limited-access data is immediately, and queitly sent away.
Oh goody.

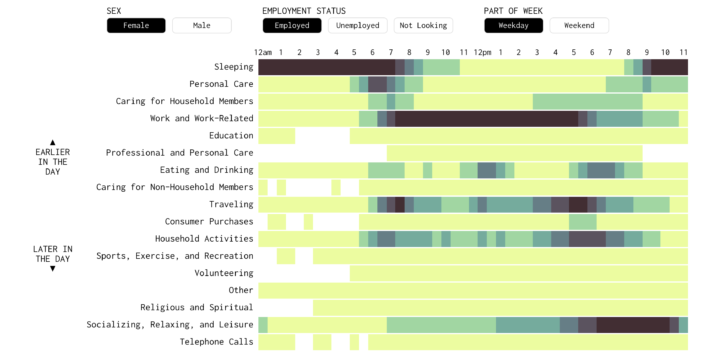
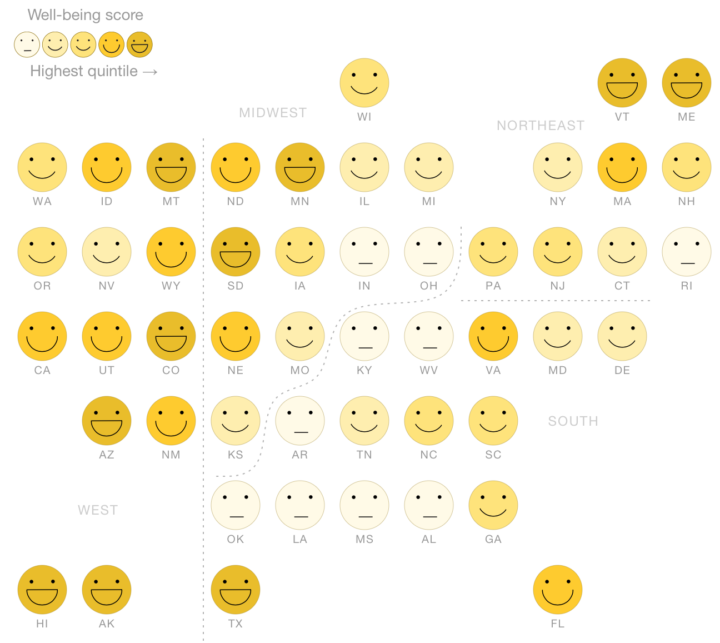
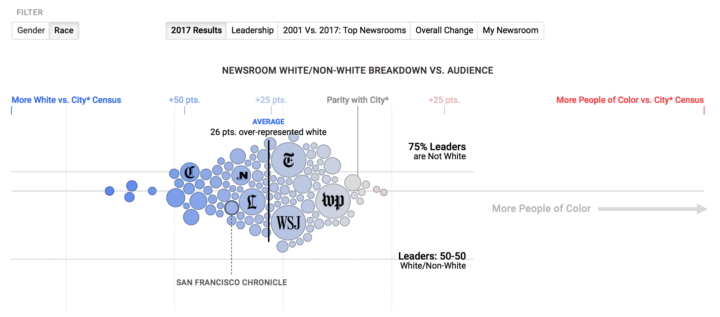

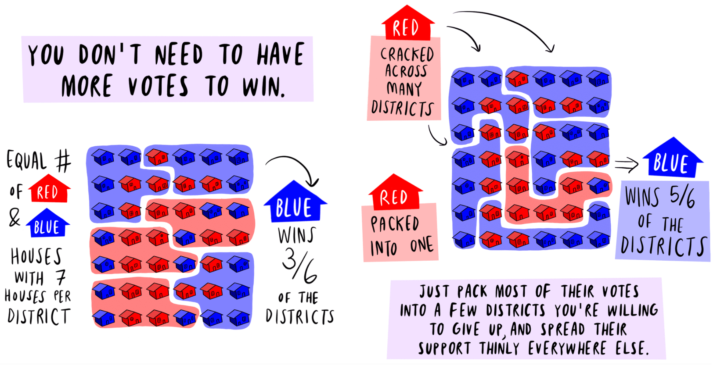
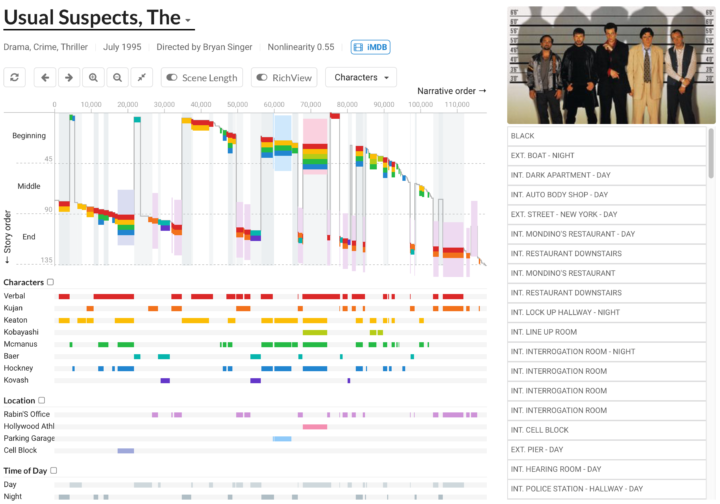
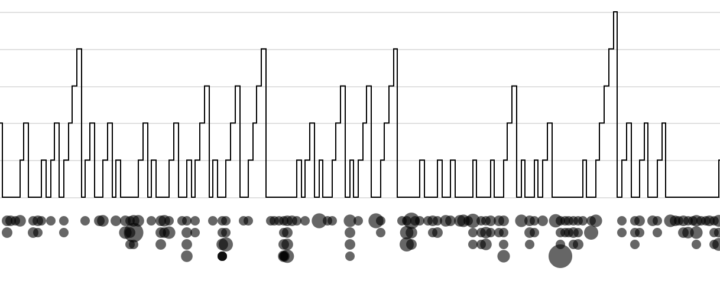

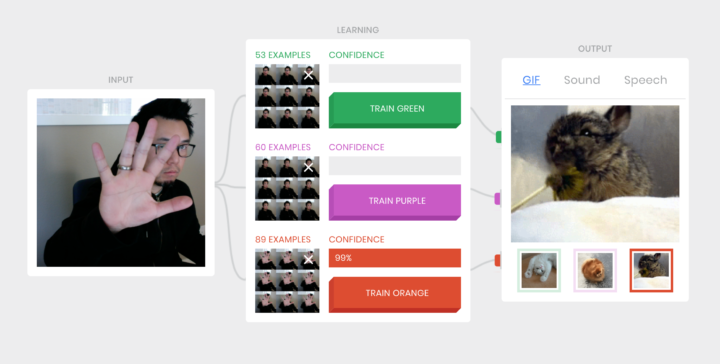

 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









