It’s December 1. ‘Tis the season for giving, so guess what – it’s time for a FlowingData contest! Jodi has kindly offered two free Edward Tufte books for one lucky FlowingData reader. She’s getting ready to move and simply wants to find these books a good home. The two books up for grabs:
-
The Visual Display of Quantitative Information — “Excellence in statistical graphics consists of complex ideas communicated with clarity, precision, and efficiency…”

-
Visual Explanations — “Our thinking is filled with assessments of quantity, an approximate or exact sense of number, amount, size, scale…”

Both books are used, but I don’t think that matters. They still have the same pretty content as they did when they were new. You know – like a fine wine. There’s nothing better than a bottle of aged Tufte.
How to Win
Below is a graph that shows immigration to the United States by country of origin. Can you make a better graph using the same data source?

To the person who submits the best remake of the above immigration graph will win both Tufte books. Email me your entries to nathan [at] flowingdata DOT com with “Graph Contest” in the subject line by Friday, December 5, 8:00pm EST. Jodi and I will judge based on informativeness (is that even a word?), aesthetics, and creativity. I will announce the winner later next week as well as post everyone’s work like I’ve done in the past. The books can only be shipped to those with a U.S. mailing address, so any international entries will have to be for pride.
Good luck. We’re looking forward to seeing what you all come up with.
P.S. Don’t forget to thank Jodi for her generous donation!
UPDATE: I should’ve mentioned this. You can submit up to two entries, and I will greatly appreciate it if your entries are in image format e.g. JPG, GIF or in PDF format rather than an Excel spreadsheet. Although it’s not a requirement. Lastly, as you design your improved graphs, you might want to take a look at some of the data design tips I’ve posted.



 The algorithm can of course be generalized to not just words and can be used with non-human images as well. Ginger the Cockapoo serves as the case study in which Jeff reconstructs an image of the dog with rectangles, the letter O, leaf-like shapes, and filled circles.
The algorithm can of course be generalized to not just words and can be used with non-human images as well. Ginger the Cockapoo serves as the case study in which Jeff reconstructs an image of the dog with rectangles, the letter O, leaf-like shapes, and filled circles. The title reads, “Barack Obama is going to appoint the nation’s first CTO. What are the top priorities?” I don’t know about you, but I’m
The title reads, “Barack Obama is going to appoint the nation’s first CTO. What are the top priorities?” I don’t know about you, but I’m 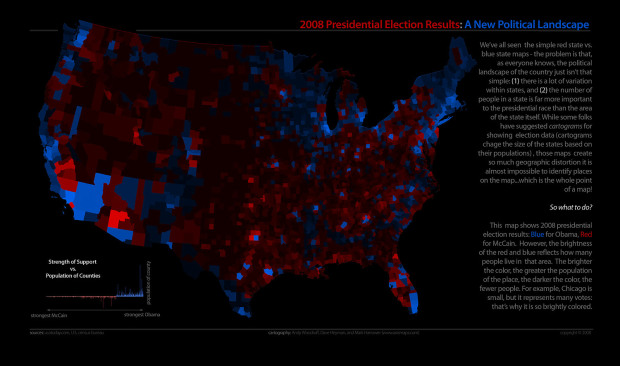
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









