Dear reader,
After much thought and arguments with myself, I’ve decided to quit data. It’s been almost two years writing for FlowingData and almost four years as a statistics graduate student, and data never stops. I think I know what postal employees feel like. Every day is just more and more data. Gimme more. Everyone wants more – but to what end? There’s too much of it. Sometimes I just want to curl up in the fetal position in the corner of my office and cry.
Why do we need data anyways? It just makes life more complicated, and educated decisions are overrated. Guesswork is underrated. So – and it pains me to say this – I’ve decided to quit FlowingData and graduate school. I will be joining a traveling entertainment troupe that eats paper. I just need one of those sticks with the back on the end of it. You know, like the ones that they show on TV… with the hobos. Forget it, I can’t remember. I’ll just get a garbage bag.
I hope you all understand. Like I said, I’ve given this a lot of thought, and this is really the best thing to do at this point of my life. Visualization, design, statistics, or computer science will never be able to handle all the data that are to come, so it’s best I part ways now before it’s too late. Keep an eye out for my paper-eating entertainment troupe. We don’t have a name yet… and it’s really just me, not so much a group. I also don’t have any paper, or actually, I do have a few post-it notes. No, that won’t be enough. Maybe I can be the used-napkin-eating person guy thing. I dunno. Well – keep an eye out. It will be the show to watch. Thanks everyone for reading and all of your support. Please do sign the guest book to stay up to date on the paper-eating napkin-eating troupe.
All the best,
Nathan
UPDATE: Just to be clear – happy april 1 :)
 The number of Web applications to collect data and information about yourself continues to grow; if you want to track something, most likely there’s an online tool to do it. This is great – especially since a lot of the applications seem to have a lot of users, which means an interest in data. Whether it is deliberate or not is a different question, but you know, that doesn’t really matter. What does matter is that people are taking notice. However, as users, developers, and designers, we shouldn’t be satisfied too quickly with what we have. Want more. Demand more. It’s interesting and oftentimes fun to log data about your life – whether it be when you go the bathroom, your sugar levels, or your mood. You get some nice graphs and charts, it looks cool, and maybe you learn something about yourself.
The number of Web applications to collect data and information about yourself continues to grow; if you want to track something, most likely there’s an online tool to do it. This is great – especially since a lot of the applications seem to have a lot of users, which means an interest in data. Whether it is deliberate or not is a different question, but you know, that doesn’t really matter. What does matter is that people are taking notice. However, as users, developers, and designers, we shouldn’t be satisfied too quickly with what we have. Want more. Demand more. It’s interesting and oftentimes fun to log data about your life – whether it be when you go the bathroom, your sugar levels, or your mood. You get some nice graphs and charts, it looks cool, and maybe you learn something about yourself.
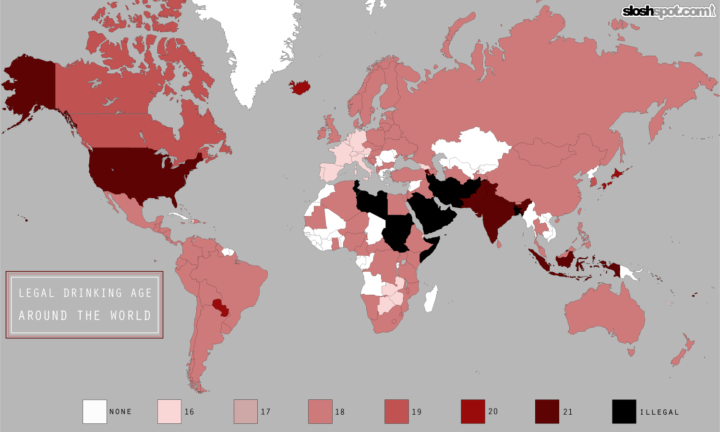
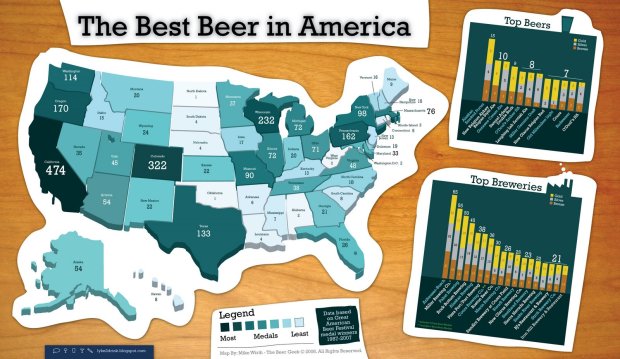
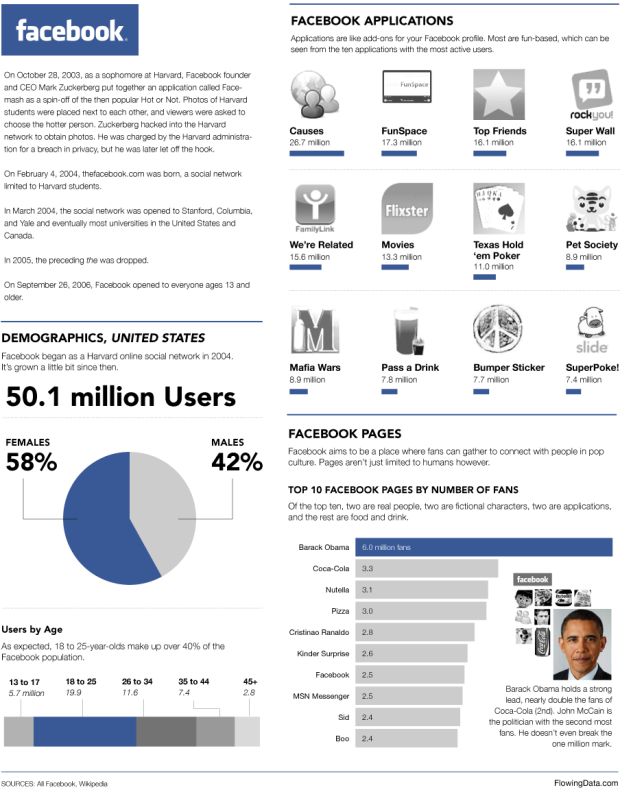
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)










{kind=link}
{kind=link}