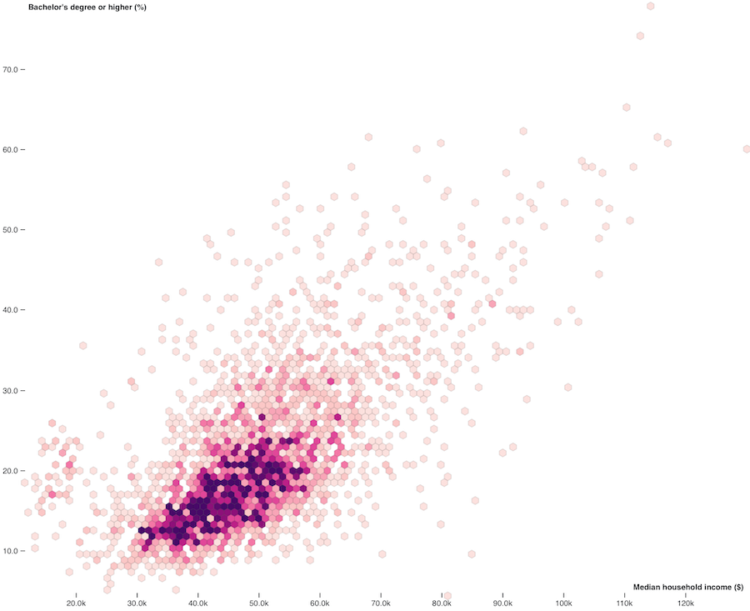
There is a lot of Census data. You can grab most of the recent aggregates through the American FactFinder or via FTP or some obscure Census page that hasn’t been updated in a decade. It’s, uh, not always the best experience. The Census Data Downloader from the Los Angeles Times data desk is a Python library that streamlines the download process, if just a little bit.
The main added value comes from a way to use existing definitions or make your own to download tables as CSV. That way you get readable headers instead of meaningless table codes.
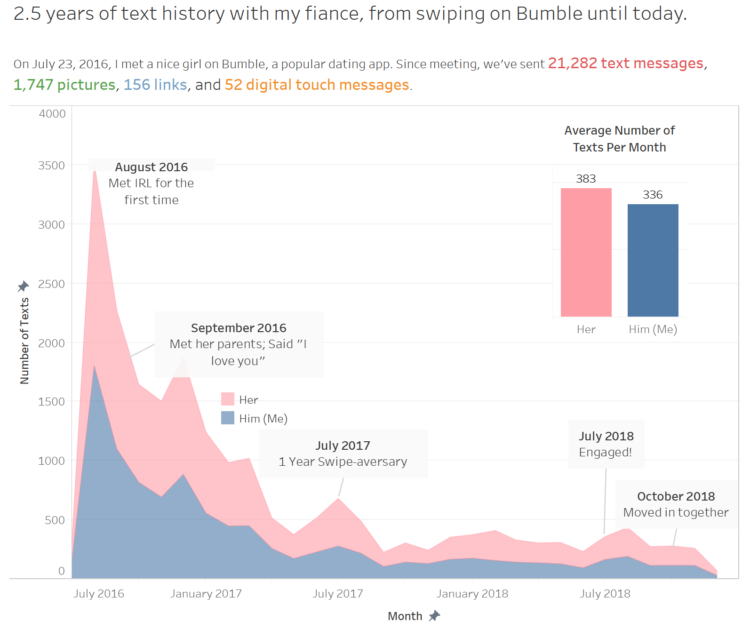
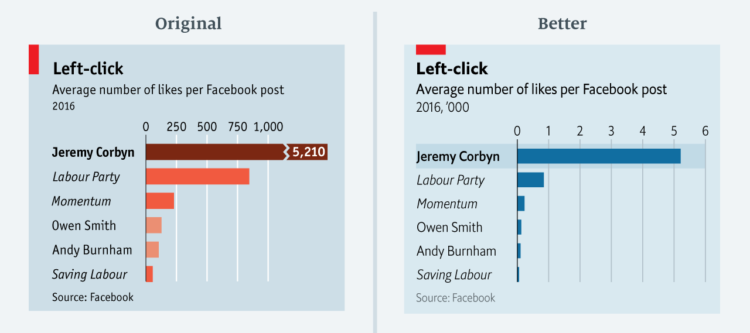

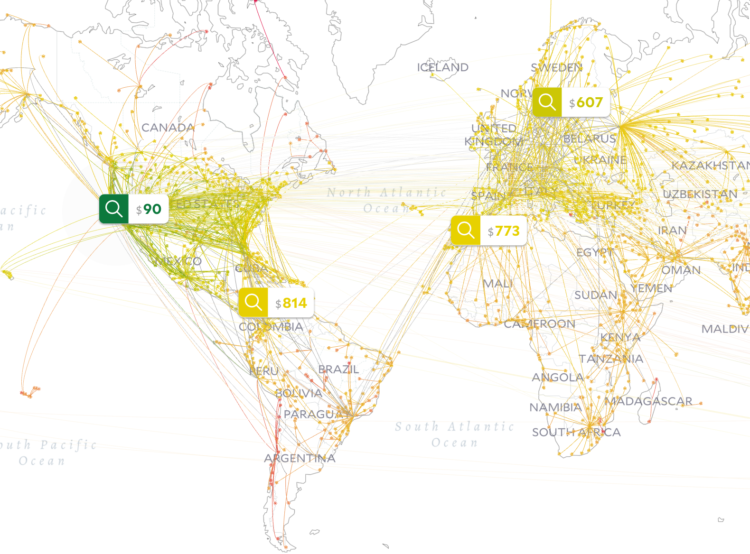

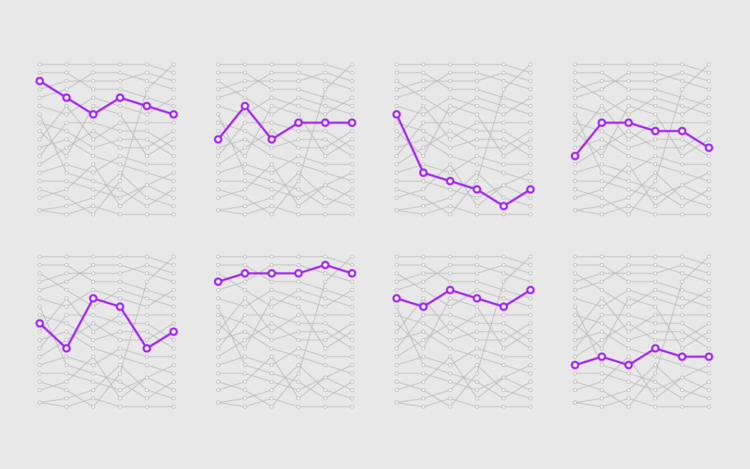

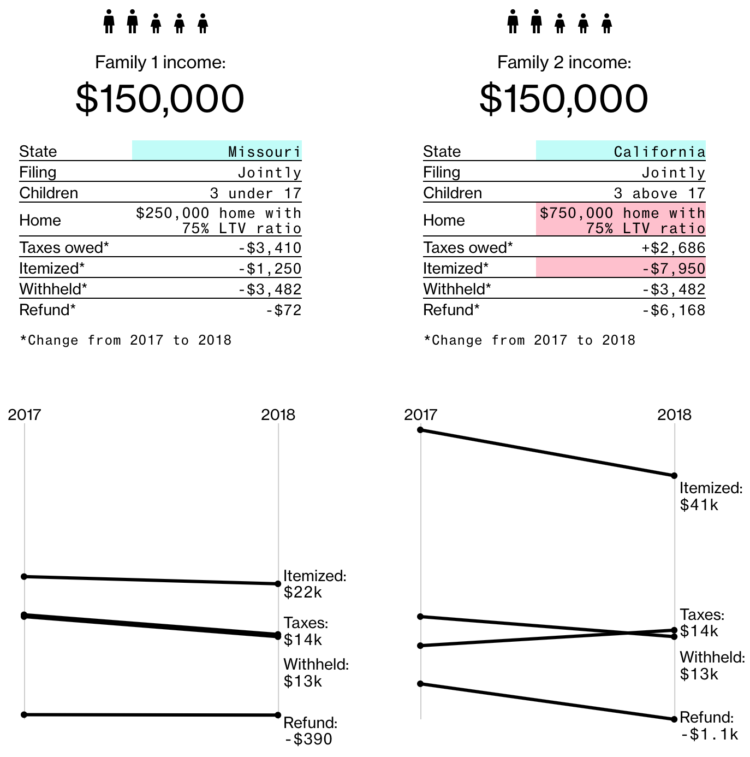

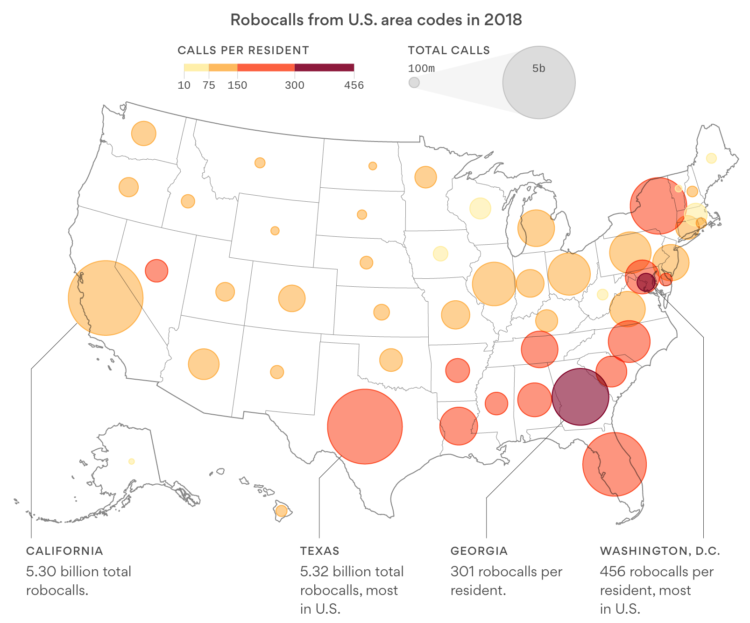
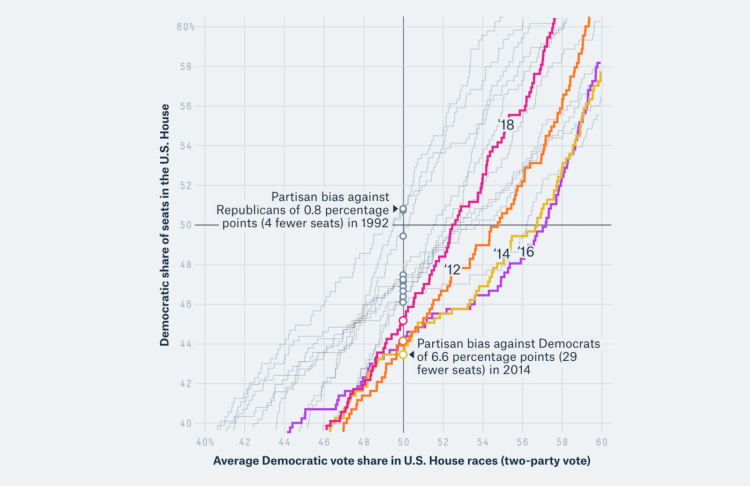
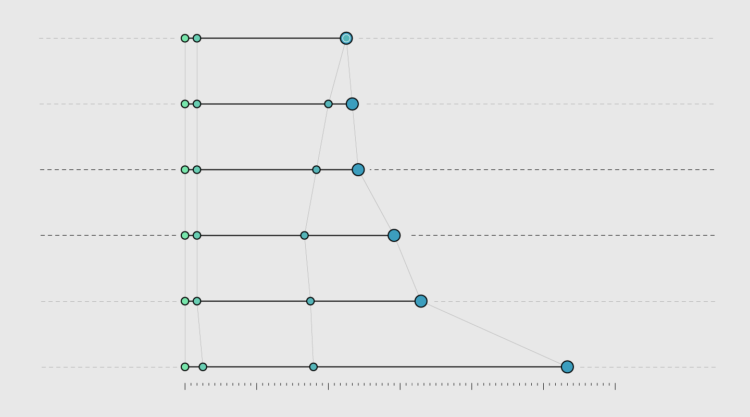

 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









