Naked Statistics by Charles Wheelan promises a fun, non-boring introduction to statistics that doesn’t leave you drifting off into space, thinking about anything that is not statistics. From the book description:
For those who slept through Stats 101, this book is a lifesaver. Wheelan strips away the arcane and technical details and focuses on the underlying intuition that drives statistical analysis. He clarifies key concepts such as inference, correlation, and regression analysis, reveals how biased or careless parties can manipulate or misrepresent data, and shows us how brilliant and creative researchers are exploiting the valuable data from natural experiments to tackle thorny questions.
 The first statistics course I took—not counting the dreadful high school stat class taught by the water polo coach—actually drew me in from the start. Plus, I needed to finish my dissertation, so I didn’t pick it up when it came out last year.
The first statistics course I took—not counting the dreadful high school stat class taught by the water polo coach—actually drew me in from the start. Plus, I needed to finish my dissertation, so I didn’t pick it up when it came out last year.
I saw it in the library the other day though, so I checked it out. If anything, I could use a few more anecdotes to better describe statistics to people before they tell me how much they hated it.
Naked Statistics is pretty much what the description says. It’s like your stat introduction course with much less math, which is good for those interested in poking at data but well, slept through Stat 101 and have an irrational fear of numbers. You get important concepts and plenty of reasons why they’re worth knowing. Most importantly, it gives you a statistical way to think about data, flaws and all. Wheelan also has a fun writing style that makes this an entertaining read.
For those who are familiar with inference, correlation, and regression, the book will be too basic. It’s not enough just for the anecdotes. However, for anyone with less than a bachelor’s degree (or equivalent) in statistics who wants to know more about analyzing data, this book should be right up your alley.
Keep in mind though that this only gets you part way to understanding your data. Naked Statistics is beginning concepts. Putting statistics into practice is the next step.
Personally, I skimmed through a good portion of the book, as I’m familiar with the material. I did however read a chapter out loud while taking care of my son. He might not be able to crawl yet, but I’m hoping to ooze some knowledge in through osmosis.
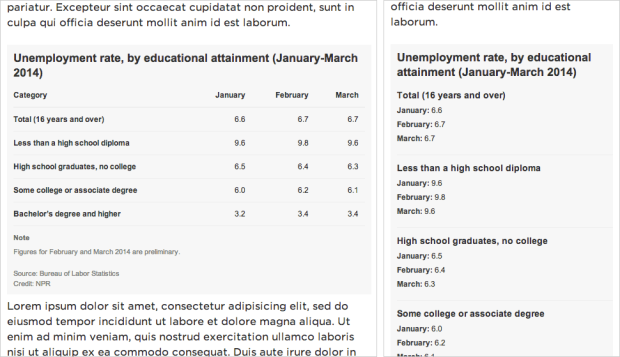
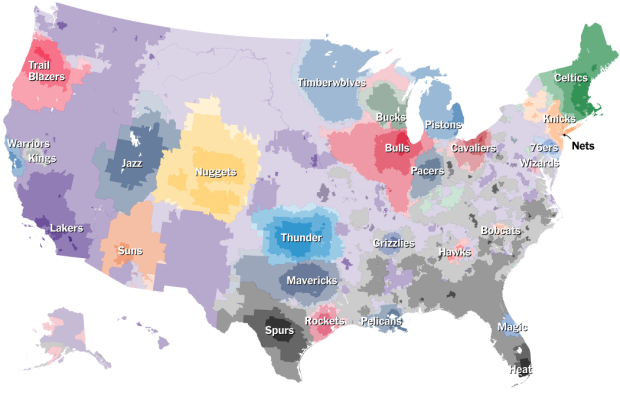
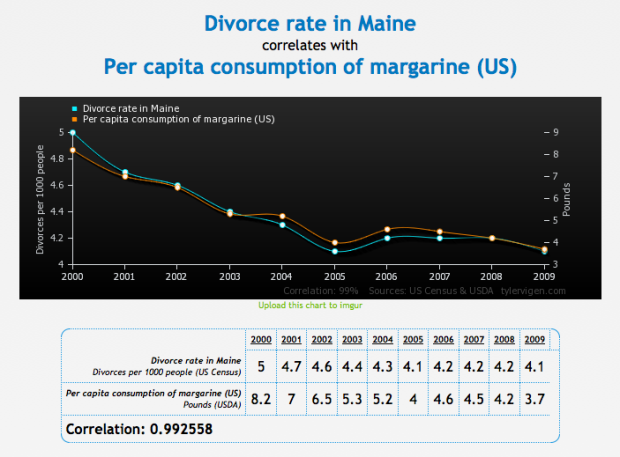

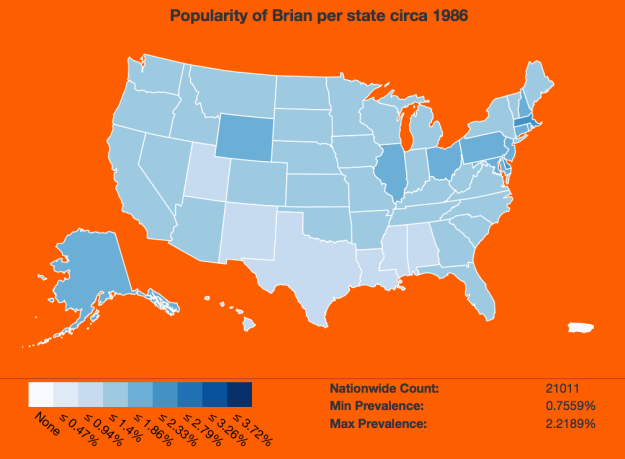


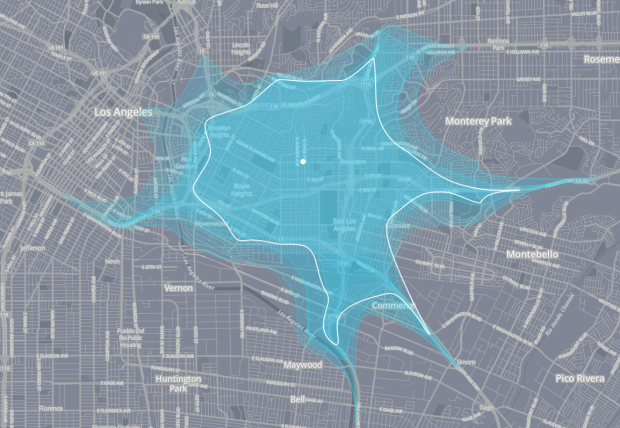
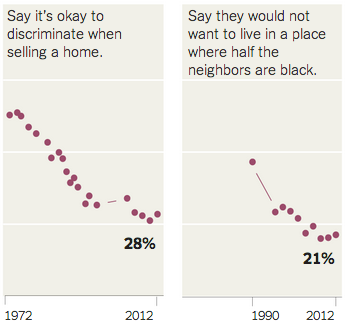
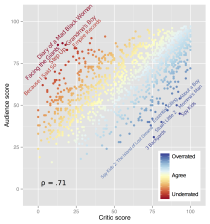 Ben Moore was
Ben Moore was  Following the lead of
Following the lead of 


 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









