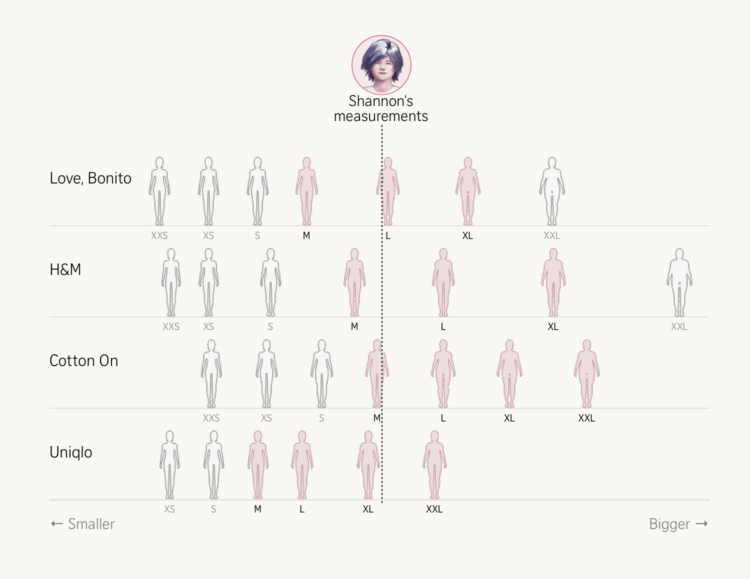
Women’s clothing sizes aren’t the same across brands. The Straits Times collected measurements, printed 3-D models, and compared size charts against reality to show variation scale and maybe help you find the right size.
Size information also varies. Some brands provide general body measurement sizing guides for all products, others list garment measurements for each item, and some offer both. Since general body measurements are easier to compare with our own, we collected body measurement charts from eight popular brands in Singapore – Uniqlo, H&M, Cotton On, Sandro, COS, Lululemon, Love & Bravery and Love, Bonito – which publish them online.
Most sizing guides often provide bust, waist and hip measurements, but bodies are more complex than a set of numbers, and that’s part of why finding a good fit can be tricky.
The article opens with a graphic similar to the Cox classic on dress sizes and then they go all-in on showing fit and clothes size. There is even this interactive bit that lets you adjust measurements to see where one might relate.

As a man with a single waist measurement and an aversion to trying on clothes, I am thankful.
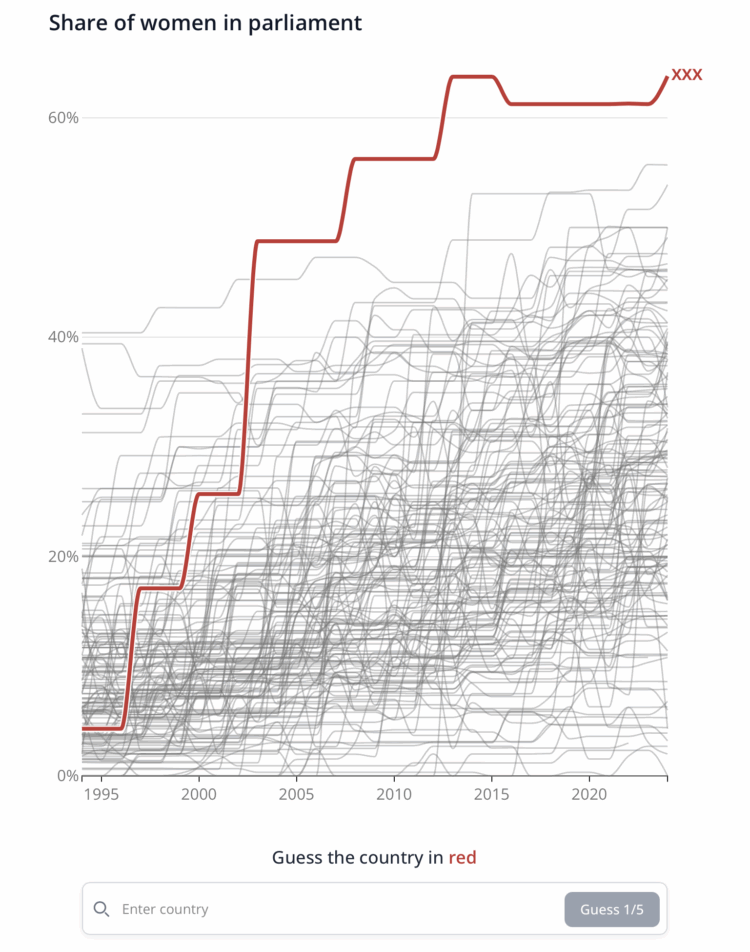
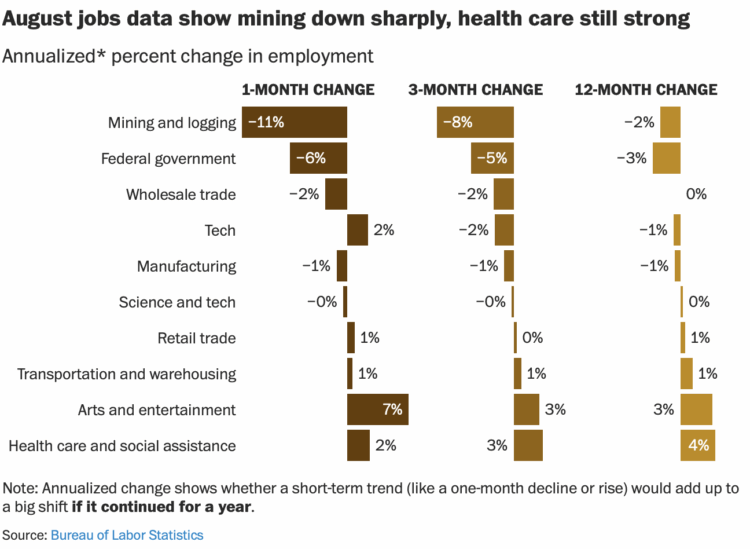
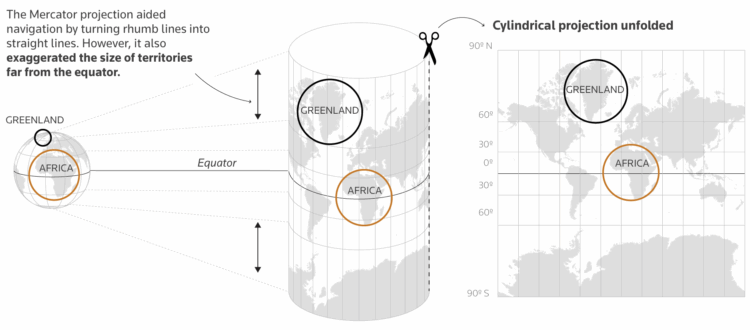

 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









