It’s been an interesting month on FlowingData. We celebrated 10,000 readers not too long ago and we’re already about to reach 12,000. I also handed out more invites to your.flowingdata, and it’s been really fun getting all the good feedback from all of you. It’s kind of overwhelming at times, but I enjoy every minute of it.
None of this would be possible without the help of FlowingData sponsors. I hope you’ll join me in thanking them by checking out the cool visualization stuff they have to offer:
Eye-Sys — Comprehensive real-time 3D visualization. Their gallery section in particular is quite impressive.
Tableau Software — Data exploration and visual analytics for understanding databases and spreadsheets that makes data analysis easy and fun.
NetCharts — Build business dashboards that turn data into actionable information with dynamic charts and graphs.
InstantAtlas — Enables information analysts to create interactive maps to improve data visualization and enhance communication.
SiSense — Easy-to-use reporting and analysis. No code required and directly connects to Excel, CSV files, SQL, MySQL, Oracle and SQL Analysis Services
If you’d like to sponsor FlowingData, please feel free to email me, and I’ll get back to you with the details.





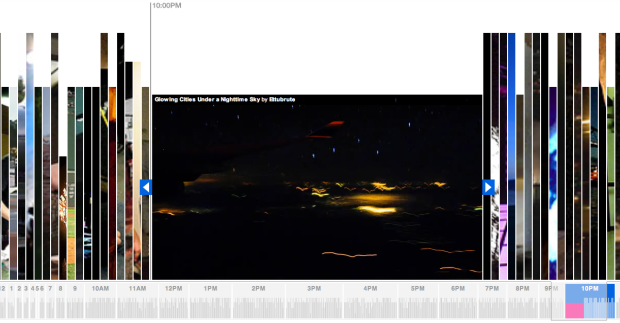



 Our 10k giveaway is now complete. Congratulations to all the winners, and a big thank you to all of you who participated. I thoroughly enjoyed some of the entries, especially the
Our 10k giveaway is now complete. Congratulations to all the winners, and a big thank you to all of you who participated. I thoroughly enjoyed some of the entries, especially the  Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)










{kind=link}