
Data checking is a pain and can be what stands between you and a good analysis or visualization session. Data Proofer aims to take away some of the pain by automating some of the process.
Every day, more and more data is created. Journalists, analysts, and data visualizers turn that data into stories and insights.
But before you can make use of any data, you need to know if it’s reliable. Is it weird? Is it clean? Can I use it to write or make a viz?
This used to be a long manual process, using valuable time and introducing the possibility for human error. People can’t always spot every mistake every time, no matter how hard they try.
Data proofer is built to automate this process of checking a dataset for errors or potential mistakes.
Gonna have to take this out for a spin.

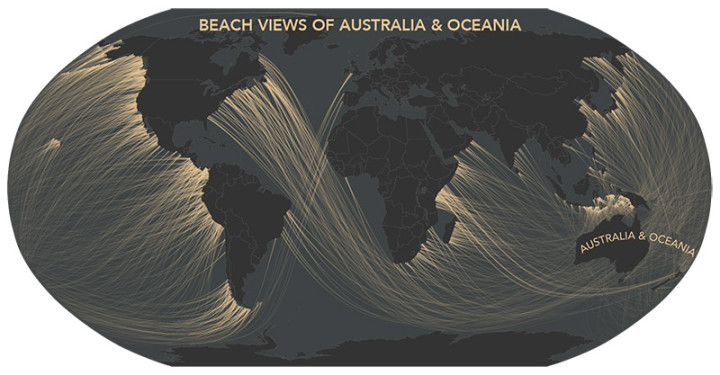





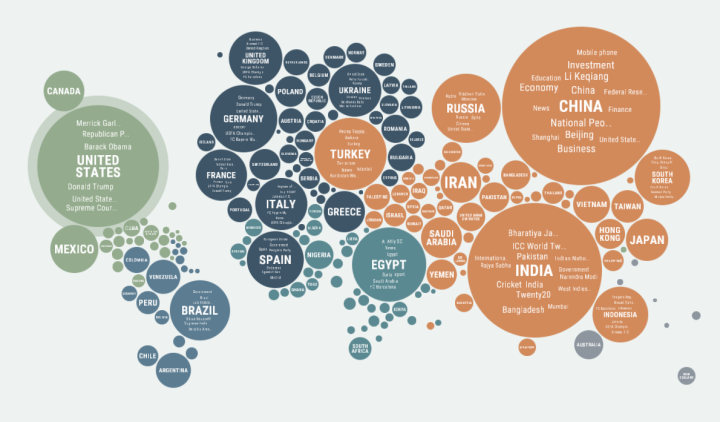
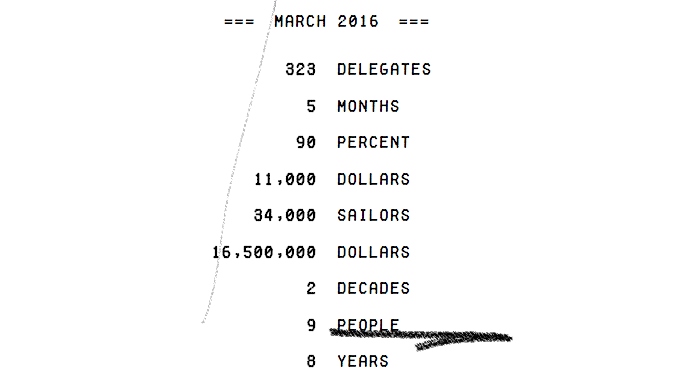
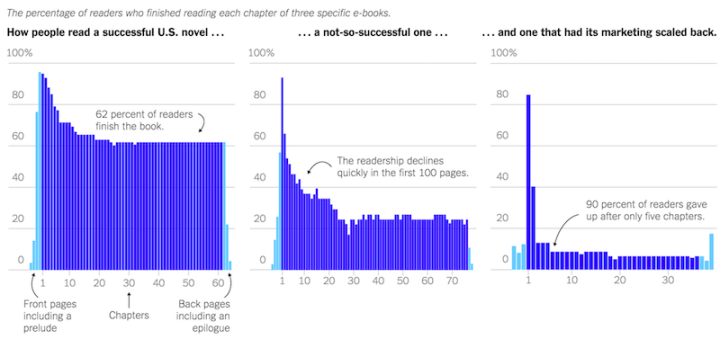
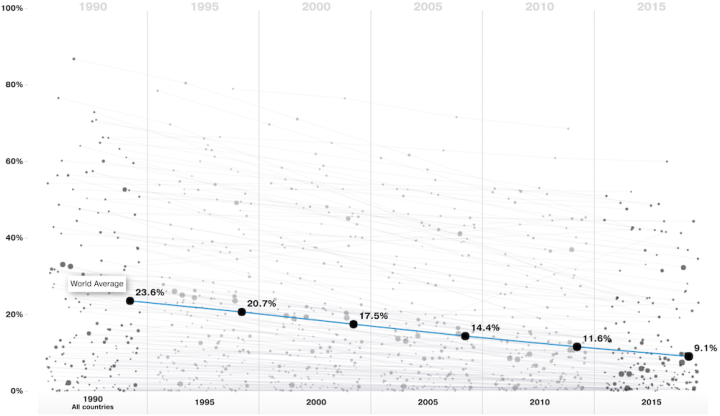
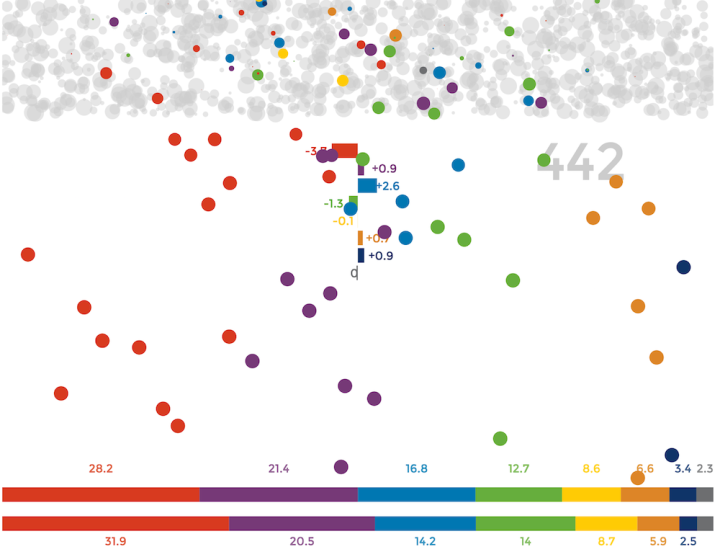
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









