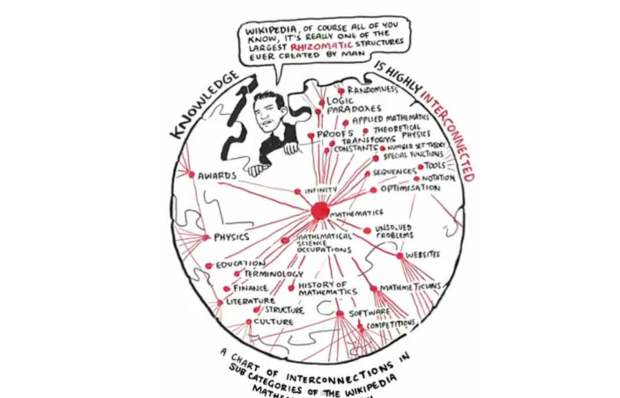
Wow, Manuel Lima, Senior UX Designer at Bing, got through a world of information in this 11 minute RSA Animate video. He spoke about the topic for which we all know him – networks. Beginning with the tree as a symbol of relationships (e.g., Aristotle’s Tree of Knowledge), Manuel then quickly sweeps through many concepts through the centuries to finally land on a modern day approach to relational information, the web or network. As trees are no longer capable of representing the complexities of the modern world, we have to find new ways to visualize these structures or perhaps even find a universal structure. His talk is loaded with beautiful examples of trees and networks.
If this fast paced animation is above your processing capacity, you can view the more austere real world video of Manuel instead. It has the bonus of an interesting interview with him in the last 6 minutes.


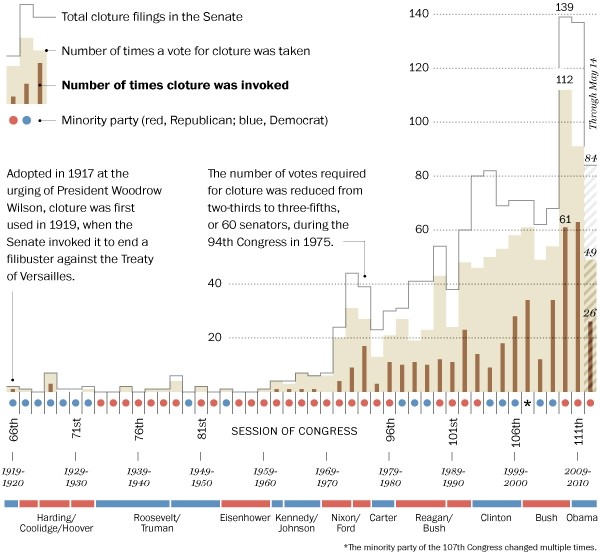
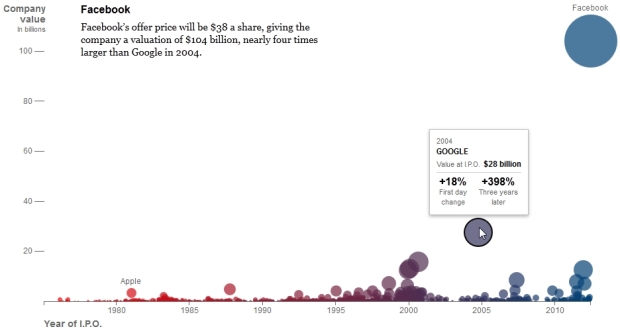
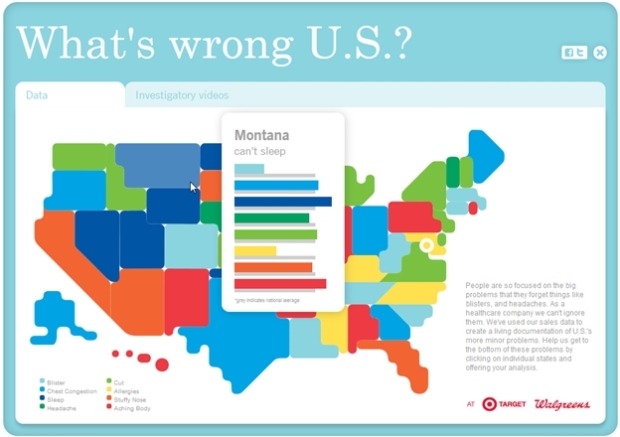
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)









