Christian Laesser takes an abstract look at how different languages represent Vincent van…
Network Visualization
Fun with links, nodes, and edges.
-
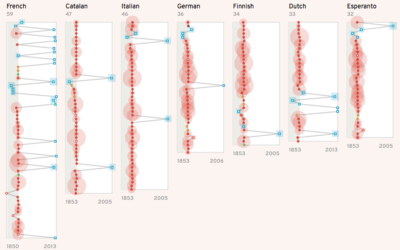
How different languages represent van Gogh
-

Star Trek character network
Star Trek fans rejoice. Mollie Pettit from Datascope Analytics visualized the interactions between…
-
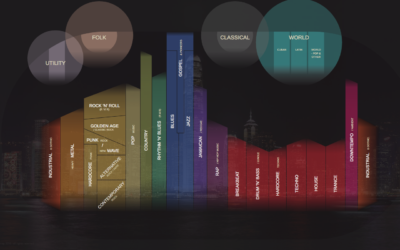
Charted history of music, from its origins to present
Musicmap is an attempt to show the history of music over time and…
-

Play chess against the machine and see what it’s thinking
The Thinking Machine, by Martin Wattenberg and Marek Walczak, shows you the thought…
-

Game of Thrones discussions for every episode, visualized
I hear there’s some show called “Game of Thrones” that’s kind of popular…
-
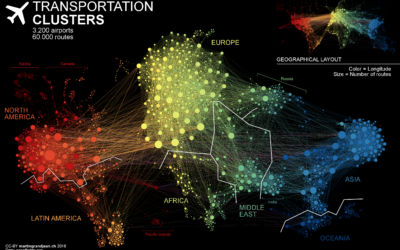
Air transportation network
Flight pattern maps are fun to look at and reveal the complexity of…
-
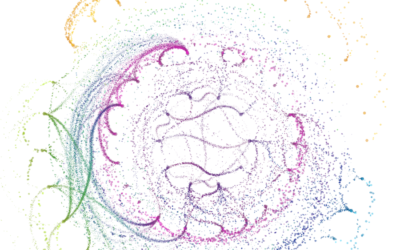
Network visualization shows transitions between states
If you think of network visualization as a collection of nodes and edges,…
-

Interconnectedness of the galaxies
A group of researchers are studying how all the galaxies in the universe…
-
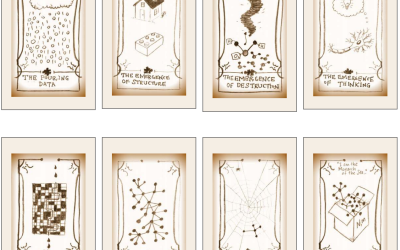
Tarot cards for complex network concepts
Peter Dodds teaches a course on complex networks, and he put together a…
-
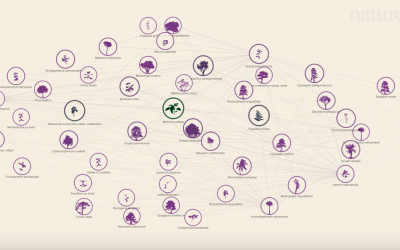
Social network of Earth’s plants and animals
Plants and animals interact with each other to stay alive, which in turn…
-

Who marries who, by profession
People with certain professions tend to marry others with a given profession. Adam…
-
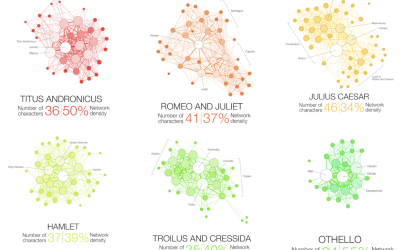
Shakespeare tragedies as network graphs
Martin Grandjean looked at the structure of Shakespeare tragedies through character interactions. Each…
-
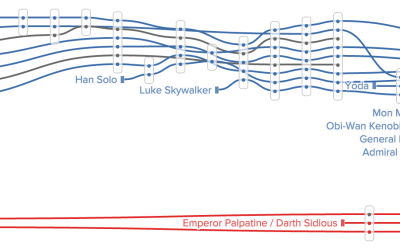
Timelines show Star Wars character interactions
Remember when xkcd charted character interactions for fictional stories? Inspired by that and…
-

Interactive lets you fly through a software galaxy
This is a fun one. Software Galaxies by Andrei Kashcha visualizes popular software…
-
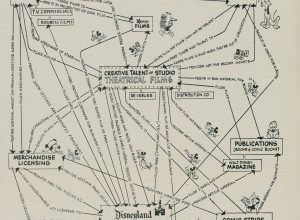
Disney business strategy chart, 1957
This is Walt Disney’s corporate strategy from 1957. The theatrical films serve as…
-

NCAA tournament bracket predictions
March Madness starts this week in the states, which means it’s time for…
-
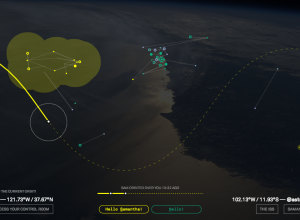
Friends in Space
Part celebration of Samantha Cristoforetti, the first Italian woman to fly into space,…
-
Neurons conversing
Adam Cohen and his group are using genetically-modified neurons that light up when…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









