Introduction to Data Science, by Harvard biostatistics professor Rafael A. Irizarry, is an…
Statistics
More than mean, median, and mode.
-

Introduction to Data Science, an open source book
-
Impossible or improbable lottery results
There was a government-run lottery in the Philippines with a $4 million jackpot,…
-
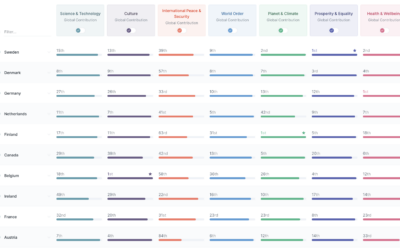
Good Country Index
The Good Country Index is an effort to highlight and rank the countries…
-
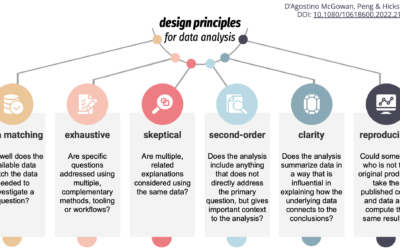
Design principles for data analysis
To teach, learn, and measure the process of analysis more concretely, Lucy D’Agostino…
-

Historical data
Randall Munroe provides another fine observation through xkcd.
I often wonder what our… -

Data horror stories song
Rafael Moral sang a very nerdy data analyst song, to the tune of…
-
Border enforcement data collection
Drew Harwell, for The Washington Post, reporting on a growing database and who…
-

Open cameras and AI to locate Instagram photos
Dries Depoorter recorded video from open cameras for a week and scraped Instagram…
-
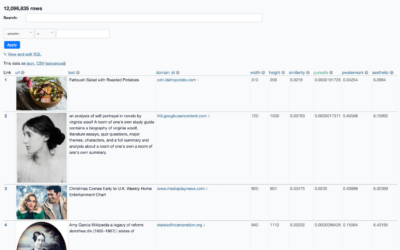
Images behind the generated images from Stable Diffusion
People have been having fun with the text-to-image generators lately. Enter a description,…
-

Introduction to Probability for Data Science, a free book
Introduction to Probability for Data Science is a free-to-download book by Purdue statistics…
-
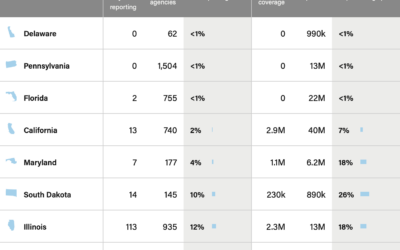
Incomplete crime data
When the FBI switched to a new data collection system, which relies on…
-
Google Maps incorrectly pointing people to crisis pregnancy centers
Davey Alba and Jack Gillum, for Bloomberg, found that Google Maps commonly points…
-
Where the data from your car flows
Jon Keegan and Alfred Ng, for The Markup, identified 37 companies that collect…
-
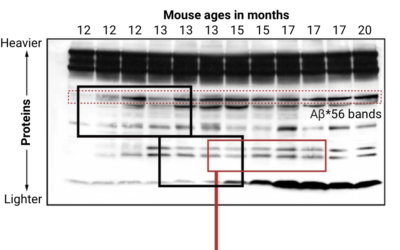
Looking for falsified images in Alzheimer’s study
Charles Piller, for Science, highlights the work of Matthew Schrag, who uses image…
-

Odds of winning the big Mega Millions prize
With tonight’s Mega Millions jackpot estimated at $1.28 billion, you might be wondering…
-
Revisiting data science, the career
In 2012, Thomas Davenport and DJ Patil outlined a budding career choice called…
-

Database of feathers
There’s a database of feathers called Featherbase, because of course there is:
Featherbase… -

Period trackers and legal implications
Given the current restrictions in the U.S., Kendra Albert, Maggie Delano, and Emma…
-

Introduction to statistical learning
An Introduction to Statistical Learning, by Gareth James, Daniela Witten, Trevor Hastie, and…
-

Communicating risk in the context of daily living
Wayne Oldford, a statistics professor at the University of Waterloo, explains risk in…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









