Traffic has been rising extra quickly these past couple of years. Unfortunately (or…
scraping
-
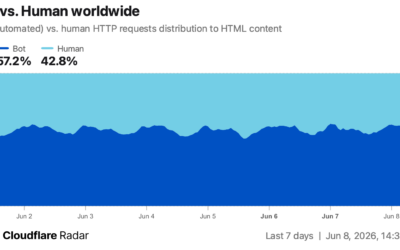
Bot traffic surpasses human traffic
-
LinkedIn sues company for fake bots
Suzanne Smalley reporting for The Record:
Social media giant LinkedIn on Thursday filed… -
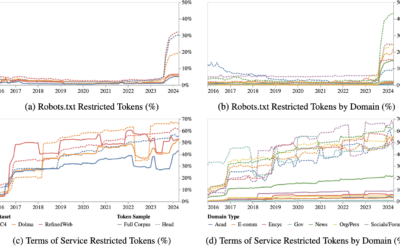
Decline in data for AI bots to scrape
The Data Provenance Initiative audited 14,000 web domains to see how sites currently…
-
News organizations blocking OpenAI
Ben Welsh has a running list of the news organizations blocking OpenAI crawlers:…
-
Scraping data without programming
Maybe you’ve wished you could quickly grab the data on a webpage and…
-
Scraping public data ruled legal
For TechCrunch, Zack Whittaker reporting:
In its second ruling on Monday, the Ninth… -
Spatula, a Python library for maintainable web scraping
This looks promising:
While it is often easy, and tempting, to write a… -

Mining Parler data
Just before the social network Parler went down, a researcher who goes by…
-
Practical tips for scraping data
It’s an unpleasant feeling when you have an idea for a project and…
-
Link
Purifying the Sea of PDF Data, Automatically →
Jeremy B. Merrill is working on the problem of too much data in PDF files. “My pattern solves this problem using tabula-extractor, the Ruby library (and command-line tool) that powers Tabula. It’s built to output data to CSVs or to a MySQL database.”
-
Link
Mining the Social Web
The example repository for Mining the Social Web if you’re interested in getting started. The Twitter examples rely on a soon to be defunct API, because the book was written in 2011, but the rest is still valid.
-

A guide for scraping data
Data is rarely in the format you want it. Dan Nguyen, for ProPublica,…
Recently for Members
Second Edition
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
New tools, refined process.
Browse by Chart Type See All →









