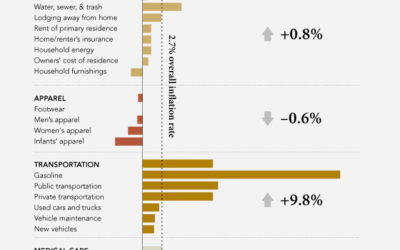
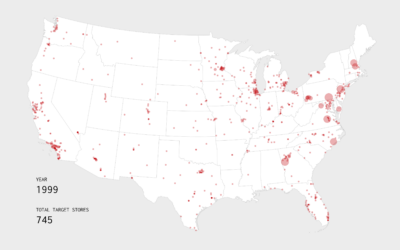
One of the main challenges of any data project is getting the data. It seems obvious, but the effort to get the right data to answer a question seems to catch people off guard. Even data that’s “free” to download can be a huge pain that ends up completely useless. ProPublica, the non-profit newsroom, deals with this stuff on a regular basis and hopes that some of their efforts can turn into a source of funding through the Data Store.
Like most newsrooms, we make extensive use of government data — some downloaded from “open data” sites and some obtained through Freedom of Information Act requests. But much of our data comes from our developers spending months scraping and assembling material from web sites and out of Acrobat documents. Some data requires months of labor to clean or requires combining datasets from different sources in a way that’s never been done before.
In the Data Store you’ll find a growing collection of the data we’ve used in our reporting. For raw, as-is datasets we receive from government sources, you’ll find a free download link that simply requires you agree to a simplified version of our Terms of Use. For datasets that are available as downloads from government websites, we’ve simply linked to the sites to ensure you can quickly get the most up-to-date data.
For datasets that are the result of significant expenditures of our time and effort, we’re charging a reasonable one-time fee: In most cases, it’s $200 for journalists and $2,000 for academic researchers.
I hope it works.