Synthetic sampling uses models to “survey” fake respondents. G. Elliott Morris and Verasight compared real polling data against the synthetic variety to find that the latter is error-prone.
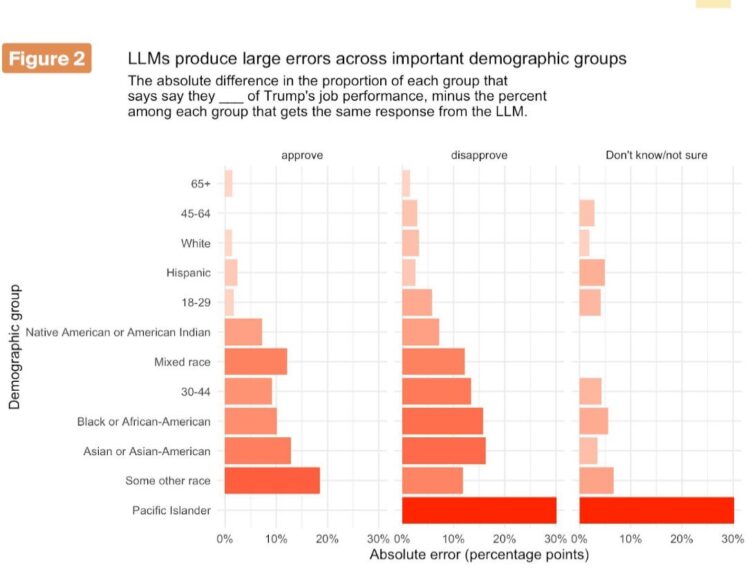
We find that the AIs cannot successfully replicate real-world data. Across models, the LLMs missed real population proportions for Trump approval and the generic ballot by between 4 and 23 percentage points. Even the best model we tested overstated disapproval of Trump, and almost never produced “don’t know” responses despite ~3% of humans choosing it.
For core demographic subgroups, the average absolute subgroup error was ~8 points; errors for some key groups (e.g., Black respondents) were as large as 15 points on Trump disapproval, and smaller groups had larger errors still (30 percentage points for Pacific Islanders). This is unusable for serious analysis.
Find the white paper here.
The point of polling is to estimate reality, so the premise of synthetic sampling through mathematical models instead of through people does not make sense to me.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)