Martin Krzywinski, whose previous work includes Circos, digs deep into the presidential debate transcripts with tedious manual (or was it automatic?) annotation of words (noun/verb/adjective/adverb), Wordle, and his custom metric called the Windbag index that measures speech complexity.
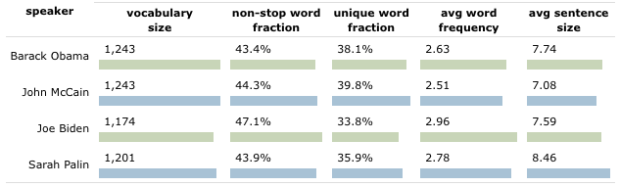
Metrics of speech structure of candidates fall within narrow tolerances, suggesting high degree of wordsmithing and rehearsal. For example, noun/verb/adjective/adverb ratio spread is very small with candidates’ values within 2%. Relatively small differences seen in unique word count and noun phrase profile. The Obama/McCain debates began with balanced performance from both candidates but end with Obama verbally overpowering McCain and delivering speech with more concepts and higher complexity. When words exclusive to a candidate are considered, Obama’s more frequent use of verbs and much more frequent use of adjectives and adverbs, compared to McCain, suggests that he is more of a fluid and contextual thinker who, unlike McCain whose language metrics suggest a categorical approach, does not seek to fit issues into pre-existing categories. Obama’s greater use of modifiers suggest an outlook that is more open to nuance and inter-relatedness of events and issues.
Wait a minute. Is this a plug from the Obama campaign? I’ve been tricked. FlowingData is non-partisan. I will reach across the aisle my friends. My friends. My friends. Joe the plumber.
All the data – transcripts, word lists, and tag clouds – are available for download in case you want to get into it yourself. Martin also dutifully supplies transcript data in Atom form, which makes it super easy to feed the data into Wordle.
Joe.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
The analysis was completely automatic. The only manual intervention was removal of transcriptionist’s marks from the transcript.
And of course it was not a plug for Obama. In order for it to be considered a plug, there’d have to be another choice. And – there is no other choice. So it’s not a plug. Right.
@Martin – much better :). I must have missed this in your report, but what did you use to annotate the text with part of speech?
Has the accuracy of Coh-Metrix been independently verified?
Also, it might be helpful to analyze extemporaneous speech in order to get an accurate representation of individuals, instead of their speech writers… ;)
Pingback: ::: Think Macro ::: » Reading blogs #3