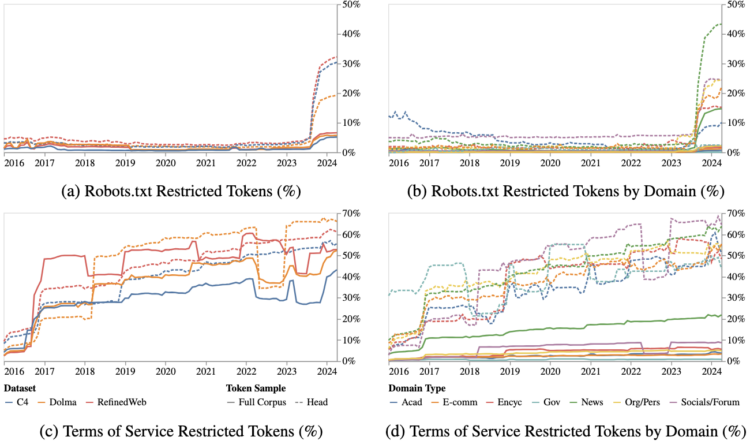
The Data Provenance Initiative audited 14,000 web domains to see how sites currently restrict scraping for the purpose of adding to AI datasets like C4, RefinedWeb, and Dolma. Sites are putting up more barriers:
Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crisis in data consent, foreclosing much of the open web, not only for commercial AI, but non-commercial AI and academic purposes.
Bots used to be a welcome thing to see in your web analytics, because it meant that your site was indexed by a search engine. Real people could find your site. However, bots for the purpose of generative AI take everything and those who run sites don’t get much, if anything, in return. The decline in data availability seems warranted.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)