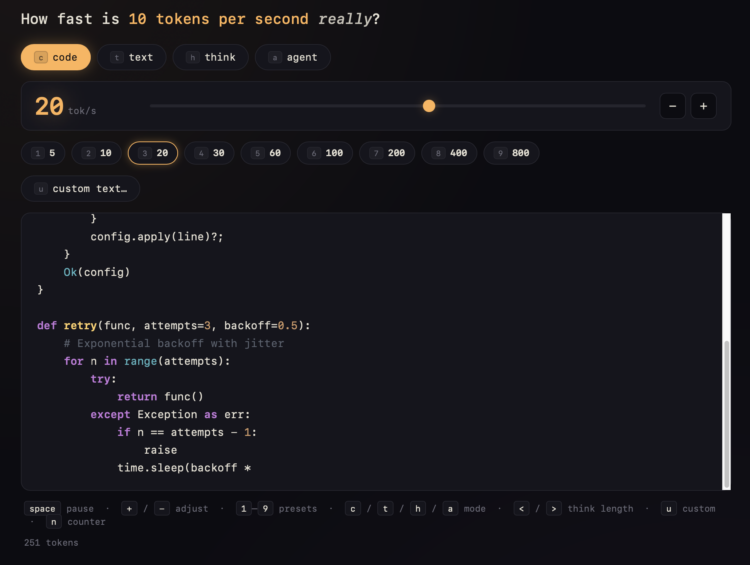
LLM speed is commonly expressed as tokens per second, which is kind of meaningless for the uninitiated. Mike Veerman made a more intuitive view for what various speeds look like.
More tokens per second means faster generation, which you can clearly see through the output appearing in the box. Select between code, text, thinking, and agent models.
I’m pretty sure the tool was made with an LLM (probably Claude based on the look and feel). The obvious next step is to go full meta to show a site that is generating itself based on the selected speed.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)