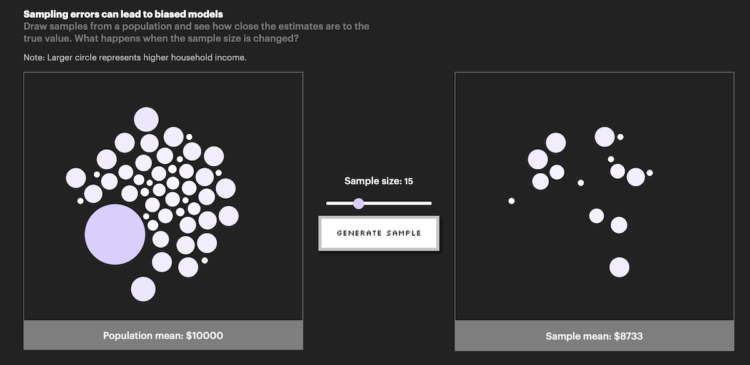
In its inaugural issue, Parametric Press describes how bias can easily come about when working with data:
Even big data are susceptible to non-sampling errors. A study by researchers at Google found that the United States (which accounts for 4% of the world population) contributed over 45% of the data for ImageNet, a database of more than 14 million labelled images. Meanwhile, China and India combined contribute just 3% of images, despite accounting for over 36% of the world population. As a result of this skewed data distribution, image classification algorithms that use the ImageNet database would often correctly label an image of a traditional US bride with words like “bride” and “wedding” but label an image of an Indian bride with words like “costume”.
Click through to check out the interactives that serve as learning aids. The other essays in this first issue are also worth a look.
 Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)
Visualize This: The FlowingData Guide to Design, Visualization, and Statistics (2nd Edition)